haje01 노트
Argo Events 와 Workflows 를 이용한 ETL
목차
준비쿠버네티스 환경
Argo Events 설치
Argo Workflows 설치
아티팩트 저장소 준비
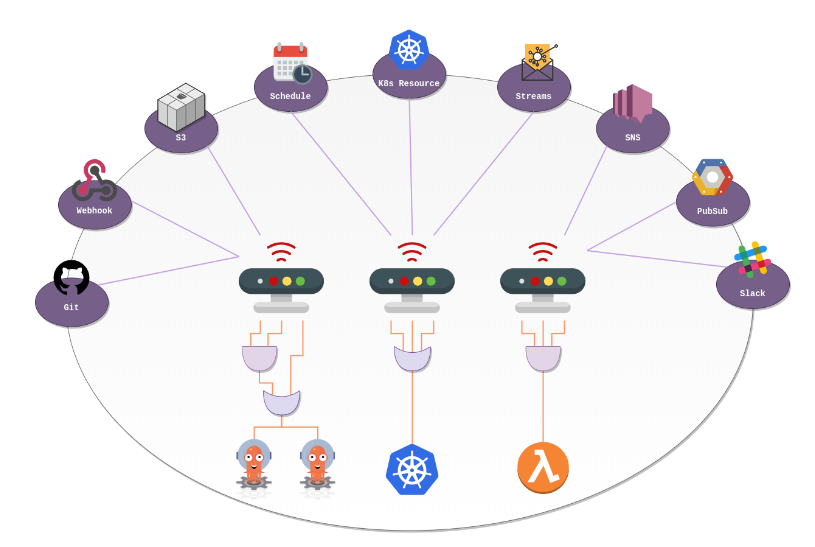
Argo Events 소개
구성 요소
Event 와 EventSource
Sensor 와 Trigger
EventBus
간단한 예제
Argo Workflows 소개
단순한 워크플로우 예제
정의 템플릿
Container 템플릿
Script 템플릿
Resource 템플릿
Suspend 템플릿
호출 템플릿
Steps 템플릿
DAG 템플릿
매개변수와 인자
글로벌 매개변수
템플릿 로컬 입력/출력 매개변수
멀티 스텝 워크플로우 예제
출력 매개변수를 사용하는 멀티 스텝 예제
DAG 워크플로우 예제
루프 예제
JSON 객체 형태의 인자로 루프 이용
DAG 에서 루프 이용
아티팩트 워크플로우 예제
ETL 맛보기
예제를 위한 컨테이너 이미지 만들기
ETL 코드 작성
워크플로우와 Secret 만들기
워크플로우 용 Service Account 만들기
MinIO 이벤트 소스 생성
MinIO 센서 생성
테스트하기
파케이 (Parquet) 파일로 저장
다수의 원본 파일 ETL 및 집계
준비 작업
불특정한 개수의 원본 파일 집계 방식
ETL 코드, 워크플로우, 이벤트 소스 작업
집계 코드 만들기
집계를 위한 EventSource 와 워크플로우
집계 Sensor 및 테스트
AWS 환경에서 ETL
EC2 인스턴스 생성
AWS SNS 주제 및 IAM 사용자 생성
SNS 이벤트 소스 만들기
SNS 와 S3 연결
ETL 코드 수정
대상 S3 버킷 접근 정보
워크플로우 만들기
센서 만들기
테스트하기
커스텀 (FTP) 이벤트 소스 예제
FTP 서버 설치
이벤트 서버와 이벤트 소스 만들기
ETL 코드, 워크플로우 그리고 센서
테스트하기
기타
재시도 설정
뮤텍스
동적인 파드 스펙 지정
워크플로우 템플릿
특정 기간에 대한 재작업
정리
참고 링크
Argo Events 와 Workflows 를 이용한 ETL
컨테이너화와 쿠버네티스는 최근 IT 업계에서 매우 중요한 기술 중 하나이다. 컨테이너화는 애플리케이션을 빠르고 안정적으로 배포할 수 있도록 해주며, 컨테이너 오케스트레이션 툴인 쿠버네티스는 컨테이너를 쉽게 관리하고 스케일링 등 다양한 기능을 제공한다.
ETL(Extract, Transform, Load)은 데이터를 추출하고, 변환하여 필요한 형식으로 가공한 다음, 저장소에 저장하는 과정을 말한다. 그렇지만 이 글은 본격적인 ETL 기술을 다루는 것이 아니며, ETL 예제를 통해 쿠버네티스 환경에서 Argo Events 와 Workflows 의 활용 방법을 보예주는 것에 초점을 맞춘다.
Argo Events 는 쿠버네티스 환경에서 이벤트 기반 워크플로우 자동화를 지원하는 툴이다. 다양한 이벤트 소스로부터 이벤트를 감지하고, 다음 워크플로우를 실행해준다. Argo Workflows 는 쿠버네티스 기반 워크플로우 엔진으로, ETL 과정의 각 단계를 효율적으로 처리할 수 있도록 도와준다. 이 둘을 결합하면 데이터 감지 및 처리 과정을 자동화하고, 효율적으로 처리할 수 있다.
예를 들어, AWS S3 버킷에 새로운 원본 파일이 업로드되면, Argo Events는 이를 감지하고, Argo Workflow 형식으로 기술된 워크플로우를 시작한다. 워크플로우는 파일을 내려받아, 필요한 변환을 수행한 다음, 결과물을 저장소에 저장하는 식이다.
이 글에서는 예제 중심으로 Argo Events 와 Workflows 의 사용법을 설명하겠다. 먼저 필요한 개념 및 준비 과정부터 시작하겠다.
준비
이 글은 Linux 환경을 전제로 설명하며, 독자가 쿠버네티스 및 관련 툴 (kubectl, helm 등) 에 대한 기본적인 지식이 있다고 가정한다.
쿠버네티스 환경
먼저 쿠버네티스 환경이 필요하다. 쿠버네티스는 다양한 배포판이 있으나, 일단 로컬에 minikube 가 설치된 것을 가정하고 진행하겠다. minikube 는 로컬 PC 에 설치 가능한 간단한 쿠버네티스 배포판이다. 설치 방법은 이곳 을 참고하기 바란다.
minikube start에서permission denied에러가 나오면 아래와 같이 해주자.sudo usermod -aG docker $USER && newgrp docker
다음으로 쿠버네티스 CLI 툴인 kubectl 을 설치 하고, 쿠버네티스 환경에 다양한 패키지를 설치하기 위해 패키지 매니저인 Helm 도 설치가 필요하다.
Argo Events 설치
Argo Events 의 최신 버전은 이곳 에서 확인할 수 있다.
여기서는 Argo Events 버전 1.7.6 을 기준으로 설명한다. Helm 을 통해 Argo 의 차트로 설치한다.
# Argo 차트 리포지토리 등록
helm repo add argo https://argoproj.github.io/argo-helm
# Argo Events 차트 설치
helm install aev argo/argo-events
추가로 이후 설명할 EventBus 의 설치가 필요하다. 다음과 같은 매니페스트를 적용하자.
kubectl apply -f - <<EOF
apiVersion: argoproj.io/v1alpha1
kind: EventBus
metadata:
name: default
spec:
nats:
native:
# 최소 3개 이상
replicas: 3
# 인증 전략
auth: none
EOF
Argo Workflows 설치
Argo Workflows 의 최신 버전은 이곳 에서 확인할 수 있다.
여기서는 Argo Workflows 버전 3.4.5 를 기준으로 설명한다. Argo Workflows 는 CLI 명령과 컨트롤러 및 서버 설치로 나뉘는데, 먼저 다음과 같이 CLI 를 설치한다.
# Download the binary
curl -sLO https://github.com/argoproj/argo-workflows/releases/download/v3.4.5/argo-linux-amd64.gz
# Unzip
gunzip argo-linux-amd64.gz
# Make binary executable
chmod +x argo-linux-amd64
# Move binary to path
mv ./argo-linux-amd64 /usr/local/bin/argo
# Test installation
argo version
컨트롤러 및 서버는 Helm 을 통해 Bitnami 의 차트 로 설치한다.
# Bitnami 차트 리포지토리 등록
helm repo add bitnami https://charts.bitnami.com/bitnami
# Argo Workflows 차트 설치
helm install awf bitnami/argo-workflows --set postgresql.enabled=false
Argo Workflows 는 관리 UI 를 제공하는데, 로그인을 위해 토큰이 필요하다. 최신 K8S 에서는 Service Account 에 기본 토큰이 없기에, 다음처럼 kubernetes.io/service-account.name 어노테이션이 있는 Secret 을 만들어야 한다.
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: awf-argo-workflows-server-secret
annotations:
kubernetes.io/service-account.name: awf-argo-workflows-server
type: kubernetes.io/service-account-token
EOF
잠시 후에 다음처럼 로그인 토큰을 얻을 수 있다.
ARGO_TOKEN="Bearer $(kubectl get secret awf-argo-workflows-server-secret -o=jsonpath='{.data.token}' | base64 --decode)"
echo $ARGO_TOKEN
UI 페이지 접속을 위해서 다음과 같이 포트포워딩이 필요하다.
kubectl port-forward svc/awf-argo-workflows-server 8046:80
이제 웹브라우저에서 http://localhost:8046 주소로 접속하고, 얻어둔 토큰을 이용해 로그인하면 된다.
아티팩트 저장소 준비
Argo Workflows 에서 아티팩트 (Artifact) 는 작업의 결과로 생성되는 리소스나 파일을 말한다. 단계별 결과물을 아티팩트의 형태로 공유할 수 있다.
아티팩트를 사용하기 위해서는 먼저 아티팩트 저장소 (Artifact Repository) 를 설정하여야 한다. Argo Workflows 에서는 S3, Azure Blob, HDFS 등 다양한 아티팩트 저장소 타입을 지원하는데, 여기서는 편의상 MinIO 를 이용하겠다.
Helm 을 통해 다음처럼 설치한다.
helm install minio bitnami/minio --set auth.rootPassword=admindjemals
MinIO 도 관리용 UI 를 제공하는데, 접속 암호는 djemals (영어 입력으로 어드민) 을 이용하면 된다.
참고로 설치 후 MinIO 루트유저의 이름과 암호는 다음과 같이 얻을 수 있다.
# MinIO 루트유저 이름 kubectl get secret minio -o jsonpath="{.data.root-user}" | base64 -d # MinIO 루트유저 암호 kubectl get secret minio -o jsonpath="{.data.root-password}" | base64 -d
MinIO UI 접속을 위해 다음처럼 포트포워딩을 해주고,
kubectl port-forward svc/minio --address 0.0.0.0 9001
웹브라우저에서 http://localhost:9001 주소로 접속 후, 앞 유저 이름과 암호로 로그인한다.
MinIO 는 포트 포워딩 후 로그인 동작이 잘 안되는 경우가 있다. 필자의 경험으로는 로그인 화면의 물결 모양이 움직이면 로그인이 잘 되고, 움직이지 않는 경우 로그인 동작이 되지 않는 듯 했다. 정확한 원인을 알 수는 없지만, 이런 경우 포트 포워딩을 재시작해보는 것을 추천한다.
이후 Create Bucket 링크를 눌러 artifact 이라는 이름의 버킷을 만든다.
실제 워크플로우가 사용할 저장소는 아티팩트 저장소 레퍼런스 로 지정해야 하는데, 쿠버네티스의 ConfigMap 을 통해 다음과 같이 실행하면 된다.
kubectl apply -f - <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
name: artifact-repositories
annotations:
workflows.argoproj.io/default-artifact-repository: default-minio-repository
data:
default-minio-repository: |
s3:
bucket: artifact
endpoint: minio:9000
insecure: true
accessKeySecret:
name: minio
key: root-user
secretKeySecret:
name: minio
key: root-password
EOF
모든 설치가 완료되었으면, 지금부터 Argo Events 및 Argo Workflows 의 기본 개념을 살펴보겠다.
Argo Events 소개
전통적인 ETL 작업에서는 특정 시간이되면 원본 데이터가 준비된 것으로 가정하고, 그 시점에 원본 데이터를 가져와 처리하는 방식을 많이 이용한다. 필자는 이런 것을 스케쥴 기반 (Schedule-Driven) ETL 로 부르는데, 일견 단순해 보이나 다음과 같은 경우에 문제가 발생하기 쉽다:
- 지정 시간에 원본 파일이 존재하지 않거나 불완전한 경우
- 지정 시간에 ETL 된 파일의 내용이 갱신되어 다시 올라오는 경우
- 지정 시간의 ETL 작업 종료 후 추가 파일이 올라오는 경우
이런 문제가 빈번한 경우 대응을 위해 모니터링 및 문제 발생시 ETL 재작업이 필요한데, 시간 및 인적 리소스의 소모가 크다.
문제를 근원적으로 해결하기 위해서는 원본 데이터가 올라오는 이벤트를 인식하고, 해당 이벤트 발생시 작업을 진행하는 이벤트 기반 (Event-Driven) 처리 방식이 필요하다. 이렇게 하면 파일이 예상보다 늦게 올라오거나, 바뀐 내용으로 다시 올라오는 경우에도 자동으로 작업이 진행되기 때문이다.
구성 요소
Argo Events 는 이러한 이벤트 기반 워크플로우 자동화 프레임워크로, 다음과 같은 구성 요소를 가진다.
Event 와 EventSource
Argo Events에서 Event 는 구체적인 이벤트를 의미하며, EventSource (이벤트 소스) 는 하나 이상의 Event 타입을 통해 고수준의 이벤트를 정의하는 역할을 한다.
단일 이벤트만 가지는 이벤트 소스가 많기에, 이벤트 타입이 이벤트 소스의 타입으로 불려지곤 한다.
아래와 같은 이벤트 타입이 있다:
- 달력
- 파일
- HTTP (웹훅)
- AWS SNS, SQS
- 쿠버네티스 리소스
- Kafka
- GitHub / GitLab
이 외에도 다양한 타입이 있으며, 필요하다면 제네릭 이벤트 소스 를 이용해 커스텀 이벤트 소스를 만들 수 있다.
이벤트 소스에 정의된 이벤트 타입의 조건이 만족되면 연결된 동작이 진행되는 식으로 사용된다.
Sensor 와 Trigger
Argo Events 에서 Sensor (센서) 는 자신이 의존하는 EventSource 가 만족되면 자신에게 등록된 하나 이상의 Trigger (트리거) 를 활성화하는 역할을 한다. Trigger 는 발생한 이벤트의 매개변수와 환경 정보를 참고해 지정된 동작을 실행한다.
아래와 같은 트리거 타입이 있다:
- HTTP
- Argo Workflows
- AWS Lambda
- 쿠버네티스 리소스
- Kafka 메시지
- 로그 (디버깅 용)
이 외에도 다양한 타입이 있으며, 필요하다면 커스텀 트리거를 만들 수 있다.
Sensor 당 하나 이상의 Trigger 를 가질 수 있으며, 이를 통해 다양한 워크플로우를 실행할 수 있다.
EventBus
Argo Events 에서 EventBus (이벤트 버스) 는 이벤트 소스를 센서로 전달해주는 쿠버네티스 커스텀 리소스이다. 동작을 위해 EventBus 는 동일 네임스페이스 내에 만들어져야 한다.
이벤트버스는 오픈소스 경량 메시지 브로커인 NATS 를 이용해 구현되었다.
간단한 예제
HTTP POST 를 통해서 워크플로우를 트리거하는 간단한 예제를 살펴보자.
아래는 웹훅 이벤트 소스를 위한 매니페스트 파일 webhook.yaml 이다. 특정 웹 엔드포인트로 요청이 오면 이벤트가 발생한다.
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: webhook
spec:
service:
ports:
- port: 12000
targetPort: 12000
webhook:
# 이벤트 소스는 하나 이상의 HTTP 서버를 띄울 수 있다.
example:
# HTTP 서버 포트
port: "12000"
# 리슨할 엔드포인트
endpoint: /example
# 허용되는 HTTP 메소드
method: POST
이를 이용해 다음처럼 웹훅 이벤트 소스를 생성한다.
kubectl apply -f webhook.yaml
아래는 로깅을 위한 센서 파일 log.yaml 이다. 지정된 이벤트 발생시 로그 메시지를 출력한다.
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: log
spec:
dependencies:
# 앞에서 정의한 웹훅 이벤트 소스가 발생하면 동작
- name: test-dep
eventSourceName: webhook
eventName: example
triggers:
- template:
name: log-trigger
log:
intervalSeconds: 1
이를 이용해 다음처럼 로그 센서를 생성한다.
kubectl apply -f log.yaml
이제 다음과 같이 지금까지 생성된 리소스를 확인할 수 있다.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
aev-argo-events-controller-manager-b99485cdf-ql8z2 1/1 Running 0 5m38s
awf-argo-workflows-controller-75686d754d-msrbg 1/1 Running 0 2m19s
awf-argo-workflows-server-588d6686bb-6qc5z 1/1 Running 0 2m19s
eventbus-default-stan-0 2/2 Running 0 4m5s
eventbus-default-stan-1 2/2 Running 0 3m53s
eventbus-default-stan-2 2/2 Running 0 3m51s
log-sensor-rp56d-f8b5b694-bs99c 1/1 Running 0 9s
webhook-eventsource-cfkdt-7fc944c598-mxlb9 1/1 Running 0 71s
예시의 파드 이름에 임의 문자열이 붙어있는데, 이 부분은 실제 실습에서 나오는 것으로 대체해 생각하자.
웹훅 이벤트 소스 webhook-eventsource-cfkdt-7fc944c598-mxlb9 파드와 로그 센서 log-sensor-rp56d-f8b5b694-bs99c 파드를 확인할 수 있다.
앞에서 만든 이벤트 버스도 확인된다. 이벤트 버스는 고가용성을 위해 3개 이상의 파드를 이용한다.
호스트에서 POST 메소드를 호출하기 위해 포트포워딩을 한다.
kubectl port-forward $(kubectl get pod -l eventsource-name=webhook -o name) 12000:12000
이제 웹훅 이벤트를 발생시키면, 이벤트 -> 이벤트 소스 -> 이벤트버스 -> 센서 -> 트리거 의 순으로 진행될 것이다. 확인을 위해 다음처럼 로그 센서 파드의 로그를 모니터링 한다.
kubectl logs -f log-sensor-rp56d-f8b5b694-bs99c
이제 다음처럼 엔드포인트로 POST 를 호출하면,
curl -d '{"message":"this is my first webhook"}' -H "Content-Type: application/json" -X POST http://localhost:12000/example
트리거가 실행된 것을 로그로 확인할 수 있다.
{"level":"info","ts":1678248798.7899067,"logger":"argo-events.sensor","caller":"log/log.go:46","msg":"{\"header\":{\"Accept\":[\"*/*\"],\"Content-Length\":[\"38\"],\"Content-Type\":[\"application/json\"],\"User-Agent\":[\"curl/7.68.0\"]},\"body\":{\"message\":\"this is my first webhook\"}}","sensorName":"log","triggerName":"log-trigger","triggerType":"Log",
...
간단한 예이지만, Argo Events 의 동작 흐름을 파악할 수 있을 것이다.
Argo Workflows 소개
Argo Workflows 는 ETL 뿐만 아니라 단위 작업들간 의존관계가 복잡한 다양한 태스크에 활용될 수 있으며, 의존성을 고려한 병렬 처리가 강점이다. 여기서는 주로 Argo Events 가 감지한 이벤트를 처리하기 위한 작업 명세 역할을 한다.
Argo Workflows 의 워크플로우 매니페스트는 쿠버네티스의 Job 과 비슷한 구성의 yaml 파일로 작성한다.
단순한 워크플로우 예제
다음은 간단한 워크플로우 매니페스트 파일의 예이다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world- # 워크플로우 이름 생성용 접두어
spec:
# 시작 템플릿
entrypoint: whalesay
# 사용할 템플릿을 정의
templates:
- name: whalesay # `whalesay` 템플릿 정의
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world"]
여기서 사용되는 docker/whalesay 컨테이너 이미지는, 인자 args 로 건네진 메시지를 텍스트로 묘사된 고래와 함께 출력해주는 간단한 기능을 한다.
위 파일을 hello-world.yaml 로 저장하고 다음처럼 Argo CLI 를 통해 실행할 수 있다.
argo submit --watch hello-world.yaml
이 경우는 이벤트를 통한 트리거링 없이, CLI 를 통해 명시적으로 워크플로우를 실행한 것이다.
--watch는 워크플로우가 완료될 때까지 정보를 계속 표시하는 옵션이다.
아래와 같이
kubectl을 이용해도 된다.kubectl create -f hello-world.yaml
다른 에러가 없다면, 성공적으로 워크플로우가 만들어진 것이다. 다른 터미널 창을 열고 CLI 를 통해 확인할 수 있다.
$ argo list
NAME STATUS AGE DURATION PRIORITY MESSAGE
hello-world-lncsd Succeeded 2m 30s 0
워크플로우 이름은 앞서 generateName 으로 기술한 hello-world- 뒤에 랜덤 문자열이 붙은 형태이다.
Argo Workflows UI 페이지에서도 생성된 워크플로우 정보와, LOGS 버튼을 클릭해 로그를 확인할 수 있다.
만약 UI 에서 워크플로우가 보이지 않는다면, NAMESPACE 가
default인지, LABELS 가 비어있는지 확인해보자.
지금까지 예제에서는 templates 아래 단일 템플릿을 정의하고 그것을 바로 실행했는데, 더 다양한 방식으로 템플릿을 이용할 수 있다. 템플릿에는 모두 6 가지 타입이 있는데, 크게 정의용 템플릿과 호출용 템플릿으로 분류한다.
정의 템플릿
정의 (Definition) 템플릿은 구체적인 단위 작업을 기술하는데 사용된다. 주로 이후에 설명할 호출 템플릿을 통해 불려지는 용도이나, entrypoint 로 지정하면 바로 실행될 수 있다.
Container 템플릿
컨테이너 템플릿은 가장 자주 사용되는 타입으로, 쿠버네티스의 컨테이너 container 필드와 같은 구조를 가진다. 컨테이너 이미지와 명령, 그리고 인자를 지정하여 실행할 수 있다.
아래 템플릿은 docker/whalesay 이미지에서 hello world 를 인자로 cowsay 명령을 실행하는 컨테이너 템플릿의 예이다.
- name: whalesay
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world"]
Script 템플릿
스크립트 템플릿은 컨테이너 템플릿을 편의상 포장한 것으로, 다른 스펙은 비슷하나 source 필드에 직접 코드를 기입할 수 있다는 점이 다르다.
다음은 파이썬 컨테이너 이미지에서 파이썬 코드로 랜덤값을 출력하는 예이다.
- name: gen-random-int
script:
image: python:alpine3.6
command: [python]
source: |
import random
i = random.randint(1, 100)
print(i)
스크립트 템플릿은 어디까지나 간단한 스크립트 실행 용도로, 많은 양의 코드를 기술하는 것은 바람직하지 않다.
스크립트 템플릿의 결과는 표준 출력
stdout으로 출력되고, 매니페스트 안의 다른 템플릿에서{{tasks.<NAME>.outputs.result}}또는{{steps.<NAME>.outputs.result}}형식으로 참조할 수 있다.
Resource 템플릿
리소스 템플릿은 쿠버네티스 클러스터의 리소스에 대해 직접 작업을 하는 타입이다. get, create, apply, delete, replace, patch 동작이 가능하다.
다음 예는 쿠버네티스의 ConfigMap 리소스를 생성 create 한다.
- name: k8s-owner-reference
resource:
action: create
manifest: |
apiVersion: v1
kind: ConfigMap
metadata:
generateName: owned-eg-
data:
some: value
Suspend 템플릿
서스펜드 템플릿은 주어진 시간동안, 또는 수동 명령이 있을 때까지 실행을 멈추고 기다리는데 사용된다. CLI 의 argo resume 명령으로 재개할 수 있다.
- name: delay
suspend:
# 20 초 대기
duration: "20s"
호출 템플릿
호출 (Invocation) 템플릿은 다른 템플릿을 호출하여 실제 작업을 진행한다. 다음과 같은 구조를 가진다.
name: # 자신의 이름
template: # 호출할 템플릿
arguments: # 호출 인자값
parameters: # 매개변수별 값
매개변수와 인자에 대해서는 이후에 자세히 설명하겠다.
Steps 템플릿
스텝스 템플릿은 하나 이상의 호출 스텝으로 구성되고, 각 스텝은 정의된 순서대로 실행된다. 각 스텝은 호출 템플릿의 리스트로 구성되는데, 리스트내 호출 템플릿은 병렬로 실행된다.
아래 예에서 steps 필드 아래에 각 스텝이 기술되어 있다. step1 이 실행된 후, step2a 와 step2b 가 동시에 실행된다.
- name: hello-hello-hello
steps:
- - name: step1 # 스텝 이름
template: prepare-data # 호출할 템플릿 이름
- - name: step2a
template: run-data-first-half
- name: step2b
template: run-data-second-half
스텝 리스트인
steps아래 호출 리스트가 기술되는 구조이기에- -로 표기된 것에 주의하자. 잘못 기술하면 다음과 같은 에러가 발생할 수 있다.Failed: cannot unmarshall spec: json: cannot unmarshal object into Go value of type []map[string]interface {}
DAG 템플릿
DAG (Directed Acyclic Graph) 는 유향 비순환 그래프 를 나타내는데, 의존 관계가 있는 하위 태스크 (task) 들을 조합해 작업을 구성할 때 유용하다.
아래 예제처럼 dag 아래 tasks 필드를 이용해 DAG 구조 템플릿을 정의하고, 태스크간 의존 관계를 기술하기 위해 depends 필드를 이용한다.
- name: diamond
dag:
tasks:
- name: A
template: echo
- name: B
depends: "A"
template: echo
- name: C
depends: "A"
template: echo
- name: D
depends: "B && C"
template: echo
Argo Workflows 의 구 버전에서는 태스크간 의존 관계 기술에
dependencies필드가 사용되었는데, 기능이 제한적이어서depends필드가 도입되었다.depends필드는 의존 태스크의 상태 및 예제의&&같은 불 (Bool) 논리 연산자도 지원한다. 자세한 것은 문서 를 참고하자.
위 예제는 다음과 같은 다이아몬드 구조를 가진다.
A
/ \
B C
\ /
D
그림에서 알 수 있듯이, 최종 스텝 D를 수행하기 위해 B 와 C 가 필요하고, B 와 C 가 수행되기 위해서는 A 가 먼저 수행되어야 한다.
매개변수와 인자
Argo Workflows 에서 매개변수 (Parameter) 와 인자 (Argument) 는 재활용성을 높이는 중요한 역할을 한다. 매개변수는 임의의 값을 받을 수 있는 변수이고, 인자는 매개변수에 넘겨주는 구체적인 값을 말한다.
글로벌 매개변수
매개변수는 워크플로우 및 템플릿에 대해 정의할 수 있는데, 워크플로우 레벨에서 정의된 매개변수를 글로벌 매개변수 (Global Paramter), 각 템플릿에서 정의된 매개변수를 로컬 매개변수 (Local Parameter) 라고 부른다.
글로벌 매개변수는 기본적으로 entrypoint 로 지정하는 시작 템플릿의 인자 (Argument) 인데, workflow.parameters.<NAME> 형식으로 모든 템플릿에서 참조될 수 있으며, CLI 로 argo submit 명령을 내릴 때 -p 옵션으로 다른 값을 지정할 수도 있다.
아래 예제에서는 spec/arguments 필드 아래에 글로벌 매개변수의 인자를 지정하고, 템플릿 명령 command 의 인자 args 가 그것을 직접 참조하고 있다. 아래 내용을 global-parameters.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: global-parameters-
spec:
# 시작 템플릿
entrypoint: whalesay
# 글로벌 매개변수의 인자. Argo CLI 로 오버라이딩 가능
arguments:
parameters:
- name: message
value: hello world
templates:
- name: whalesay
container:
image: docker/whalesay:latest
command: [cowsay]
# 글로벌 매개변수를 직접 참조
args: ["{{workflow.parameters.message}}"]
다음처럼 적용하면,
argo submit --watch global-parameters.yaml
워크플로우에서 지정된 인자 hello world 가 로그에 출력되지만 다음과 같이 적용하면,
argo submit --watch global-parameters.yaml -p message="goodbye world"
argo submit 명령의 옵션으로 지정된 인자 goodbye world 가 출력되는 것을 로그에서 확인할 수 있다.
템플릿 로컬 입력/출력 매개변수
앞선 예제는 템플릿 명령의 인자가 직접 글로벌 매개변수를 참조하였지만, 템플릿에 입력 매개변수 를 정의하고, 템플릿 명령 command 의 인자 args 가 inputs.parameters.<NAME> 형식으로 그것을 참조하도록 할 수도 있다.
입출력 매개변수는 정의 템플릿에서 사용된다.
아래 내용을 arguments-parameters.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: arguments-parameters-
spec:
# 시작 템플릿
entrypoint: whalesay
# 글로벌 매개변수의 인자. Argo CLI 로 오버라이딩 가능
arguments:
parameters:
- name: message
value: hello world
templates:
- name: whalesay
# 템플릿 입력 매개변수
inputs:
parameters:
- name: message
container:
image: docker/whalesay:latest
command: [cowsay]
# 템플릿 입력 매개변수를 참조
args: ["{{inputs.parameters.message}}"]
다음 처럼 적용한다.
argo submit --watch arguments-parameters.yaml -p message="goodbye world"
컨테이너 명령의 인자가 템플릿의 입력 매개변수를 참조하도록 바뀌었지만, 결과는 아까와 동일하다.
출력 매개변수 는 템플릿 호출 결과 파일의 내용을 매개변수의 값으로 이용할 수 있게 해준다. 자세한 예제는 이후에 살펴보겠다.
입력과 출력에는 매개변수 외에도 다양한 필드를 지정하여 사용할 수 있다.
이제 호출 템플릿을 이용하는 예제를 살펴보겠다.
멀티 스텝 워크플로우 예제
아래는 정의된 템플릿을 한 번 이상 순차적으로, 혹은 동시에 호출하여 작업을 구성하는 예제이다. 이를 위해 steps 필드 아래에 호출을 기술하고 있다. 내용을 steps.yaml 파일로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: steps-
spec:
# 시작 템플릿
entrypoint: hello-hello-hello
templates:
# 템플릿 정의
- name: whalesay
# message 변수를 템플릿 입력으로
inputs:
parameters:
- name: message
container:
image: docker/whalesay
command: [cowsay]
# 템플릿 매개변수를 명령 인자로 사용
args: ["{{inputs.parameters.message}}"]
# 스텝스 호출 템플릿
- name: hello-hello-hello
steps:
# 1. hello1
- - name: hello1
template: whalesay
# 매개변수별 인자값
arguments:
parameters: [{name: message, value: "hello1"}]
# 2. hello2a, hello2b
- - name: hello2a
template: whalesay
# 매개변수별 인자값
arguments:
parameters: [{name: message, value: "hello2a"}]
- name: hello2b
template: whalesay
# 매개변수별 인자값
arguments:
parameters: [{name: message, value: "hello2b"}]
다음처럼 실행하면,
argo submit --watch steps.yaml
아래와 같은 출력이 나올 것이다.
Name: steps-wk5m5
Namespace: argo
ServiceAccount: unset (will run with the default ServiceAccount)
Status: Succeeded
Conditions:
PodRunning False
Completed True
Created: Mon Mar 06 18:43:10 +0900 (30 seconds ago)
Started: Mon Mar 06 18:43:10 +0900 (30 seconds ago)
Finished: Mon Mar 06 18:43:40 +0900 (now)
Duration: 30 seconds
Progress: 3/3
ResourcesDuration: 18s*(1 cpu),18s*(100Mi memory)
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ steps-wk5m5 hello-hello-hello
├───✔ hello1 whalesay steps-wk5m5-whalesay-1602185977 6s
└─┬─✔ hello2a whalesay steps-wk5m5-whalesay-3712874914 9s
└─✔ hello2b whalesay steps-wk5m5-whalesay-3696097295 6s
hello1 이 먼저 실행된 후, hello2a 와 hello2b 가 동시에 실행되는 것을 보여주는데, UI 에서 좀 더 확실히 확인할 수 있다.
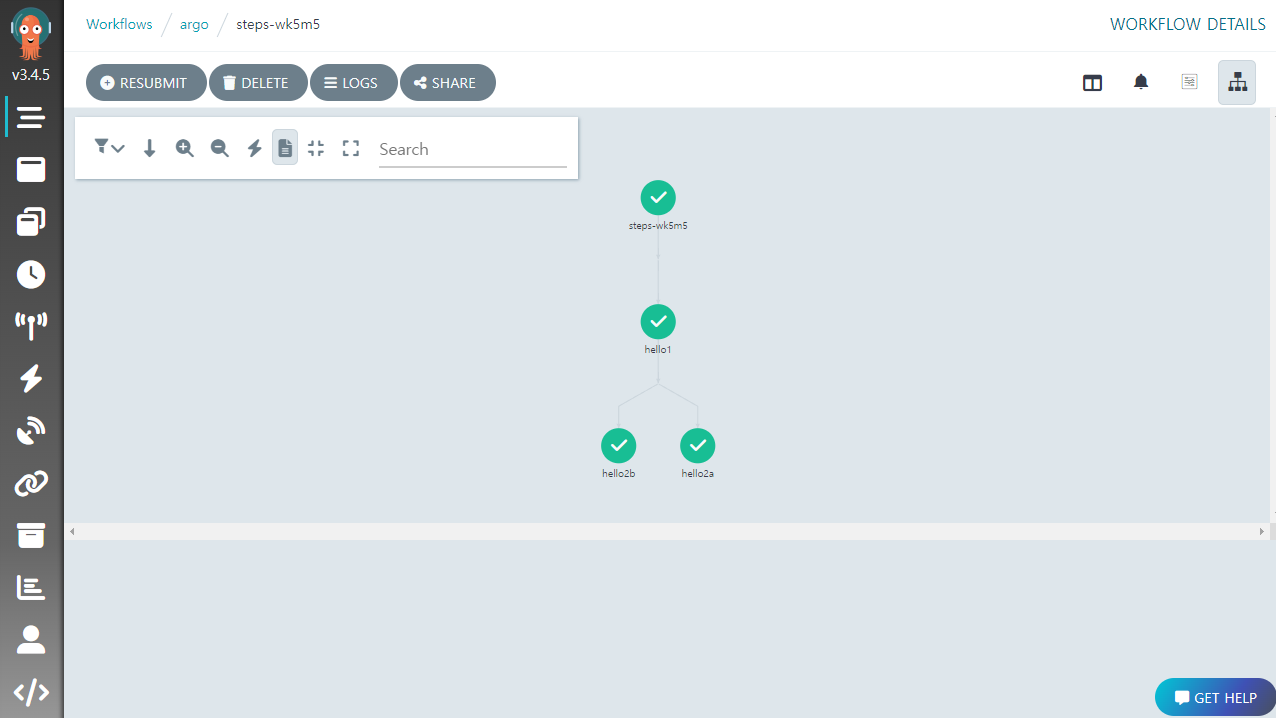
kubectl 로 보면 각 템플릿 호출마다 파드가 생성된 것을 확인할 수 있다.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
argo-server-fb8f5967d-tlqs5 1/1 Running 0 3h54m
steps-wk5m5-whalesay-1602185977 0/2 Completed 0 6m1s
steps-wk5m5-whalesay-3696097295 0/2 Completed 0 5m51s
steps-wk5m5-whalesay-3712874914 0/2 Completed 0 5m51s
workflow-controller-78f7ffdf79-7rctb 1/1 Running 0 3h55m
어떤 파드가 어떤 호출에 속하는지는 파드 정보의
Annotations블럭을 보면 알 수 있다. 예를 들면 아래와 같은 식이다.$ kubectl describe pod steps-wk5m5-whalesay-1602185977 ... Annotations: workflows.argoproj.io/node-name: steps-wk5m5[0].hello1 ...
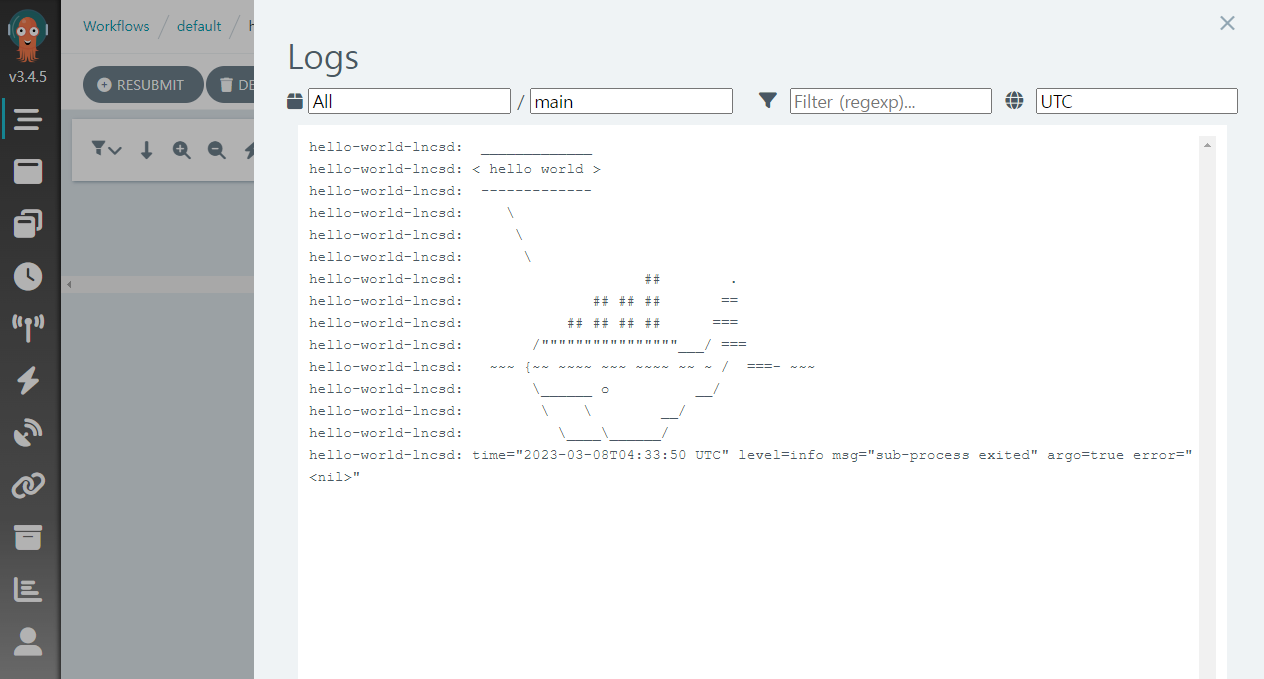
파드의 로그를 확인해보면 아래와 같이 호출시 지정된 인자로 공용 템플릿 whalesay 이 수행된 것을 알 수있다.
hello1 호출 로그
_________
< hello1 >
---------
\
\
\
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
hello2a 호출 로그
_________
< hello2a >
---------
\
\
\
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
hello2b 호출 로그
_________
< hello2b >
---------
\
\
\
## .
## ## ## ==
## ## ## ## ===
/""""""""""""""""___/ ===
~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
\______ o __/
\ \ __/
\____\______/
출력 매개변수를 사용하는 멀티 스텝 예제
여기서는 앞서 소개한 출력 매개변수를 이용하는 멀티 스텝 예제를 살펴보겠다.
입력 매개변수는 컨테이너 및 스크립트 템플릿에서 모두 사용되나, 출력 매개변수는 컨테이너 템플릿에서만 필요하다 (스크립트 템플릿은 표준출력 결과가 자동으로 outputs.result 에 들어감).
컨테이너 템플릿은 하나 이상의 출력 매개변수를 가질 수 있다.
다음 예제에서 whalesay 컨테이너 템플릿은, 실행 결과 파일 /tmp/hello_world.txt 의 내용을 출력 매개변수 hello-param 의 값으로 지정한다. 호출시 이 템플릿 출력값은 다음 스텝의 print-message 의 입력 매개변수로 넘겨진다.
아래 내용을 output-parameter.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: output-parameter-
spec:
# 시작 템플릿
entrypoint: output-parameter
templates:
# 템플릿 정의
- name: whalesay
container:
image: docker/whalesay:latest
command: [sh, -c]
args: ["sleep 1; echo -n hello world > /tmp/hello_world.txt"]
outputs:
parameters:
- name: hello-param
valueFrom: # 출력 매개변수의 값 소스
path: /tmp/hello_world.txt # 값을 얻을 파일 경로
default: "Foobar" # 지정된 경로의 파일이 없으면 이 값을 이용
- name: print-message
# 입력 매개변수
inputs:
parameters:
- name: message
container:
image: docker/whalesay:latest
command: [cowsay]
# 입력 매개변수의 값을 명령 인자로 이용
args: ["{{inputs.parameters.message}}"]
# 호출 템플릿
- name: output-parameter
steps:
# 매개변수 생성
- - name: generate-parameter
template: whalesay
# 매개변수 출력
- - name: consume-parameter
template: print-message
# 선행 스텝의 출력 매개변수에서 인자값을 얻음
arguments:
parameters:
- name: message
value: "{{steps.generate-parameter.outputs.parameters.hello-param}}"
다음처럼 적용한다.
argo submit --watch output-parameter.yaml
generate-parameter 호출의 결과가 consume-parameter 를 통해 출력되는 것을 로그에서 확인할 수 있다.
DAG 워크플로우 예제
아래는 앞서 본 다이아몬드 구조 워크플로우의 예이다. 멀티 스텝보다 복잡한 트리 구조를 표현할 수 있다. DAG 구조 템플릿 정의를 위해 dag 필드를, 호출의 의존 관계를 기술하기 위해 depends 필드를 이용한다. 내용을 dag-diamond.yaml 파일로 저장한다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: dag-diamond-
spec:
# 시작 템플릿
entrypoint: diamond
templates:
# 공통 템플릿 정의
- name: echo
inputs:
parameters:
- name: message
container:
image: alpine:3.7
command: [echo, "{{inputs.parameters.message}}"]
# 공통 템플릿을 호출하는 DAG
- name: diamond
dag:
tasks:
- name: A
template: echo
arguments:
parameters: [{name: message, value: A}]
- name: B
depends: "A" # A 에 의존
template: echo
arguments:
parameters: [{name: message, value: B}]
- name: C
depends: "A" # A 에 의존
template: echo
arguments:
parameters: [{name: message, value: C}]
- name: D
depends: "B && C" # B 와 C 에 의존
template: echo
arguments:
parameters: [{name: message, value: D}]
하나 이상의 선행 호출을 의존하는 D 의 경우 B && C 형태로 기술하였다.
의존 관계를 위해 다양한 논리 연산을 지원하는 데, 자세한 것은 공식 페이지 를 참고하자.
다음처럼 실행하면,
argo submit --watch dag-diamond.yaml
아래와 같은 출력이 나올 것이다.
Name: dag-diamond-d6xfs
Namespace: argo
ServiceAccount: unset (will run with the default ServiceAccount)
Status: Succeeded
Conditions:
PodRunning False
Completed True
Created: Tue Mar 07 12:00:27 +0900 (40 seconds ago)
Started: Tue Mar 07 12:00:27 +0900 (40 seconds ago)
Finished: Tue Mar 07 12:01:07 +0900 (now)
Duration: 40 seconds
Progress: 4/4
ResourcesDuration: 16s*(1 cpu),16s*(100Mi memory)
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ dag-diamond-d6xfs diamond
├─✔ A echo dag-diamond-d6xfs-echo-1891072275 8s
├─✔ B echo dag-diamond-d6xfs-echo-1907849894 4s
├─✔ C echo dag-diamond-d6xfs-echo-1924627513 4s
└─✔ D echo dag-diamond-d6xfs-echo-1941405132 4s
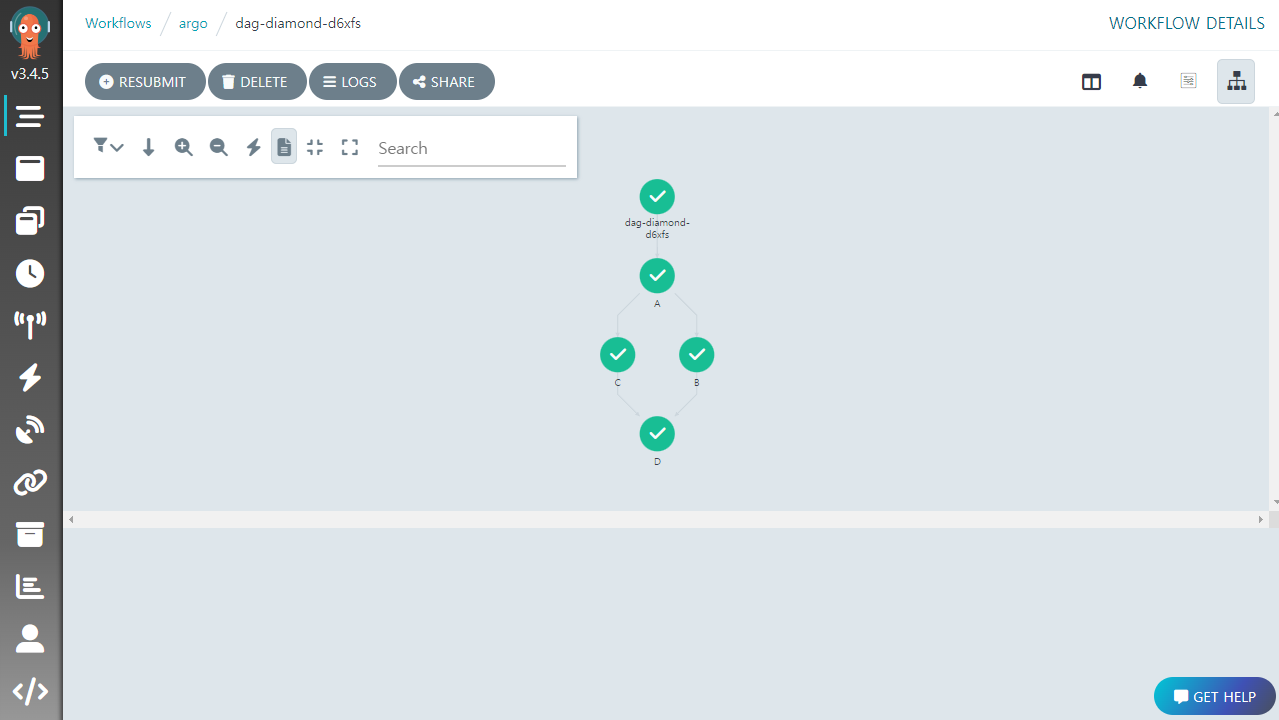
이 출력 만으로는 DAG의 구조를 파악하기가 쉽지 않다. UI 에서 살펴보면 확실히 알 수 있다.
루프 예제
워크플로우 내에서 템플릿이 다양한 인자로 여러번 호출되어야 하는 경우 여기서 소개하는 루프 (Loop) 기능을 이용하면 편리하다.
다음 내용을 loops.yaml 이라는 이름으로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: loops-
spec:
# 시작 템플릿
entrypoint: loop-example
templates:
# 정의 템플릿
- name: whalesay
inputs:
parameters:
- name: message
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
# 호출 템플릿
- name: loop-example
steps:
- - name: print-message
template: whalesay
arguments:
parameters:
- name: message
value: "{{item}}"
# whalesay 템플릿을 아래의 두 인자값으로 동시에 각각 호출한다.
withItems:
- hello world # item 1
- goodbye world # item 2
다음처럼 적용하면,
argo submit --watch loops.yaml
whalesay 템플릿이 withItems 필드에서 지정된 hello world 와 goodbye world 의 두 인자값으로 각각 동시에 호출되는 것을 확인할 수 있다.
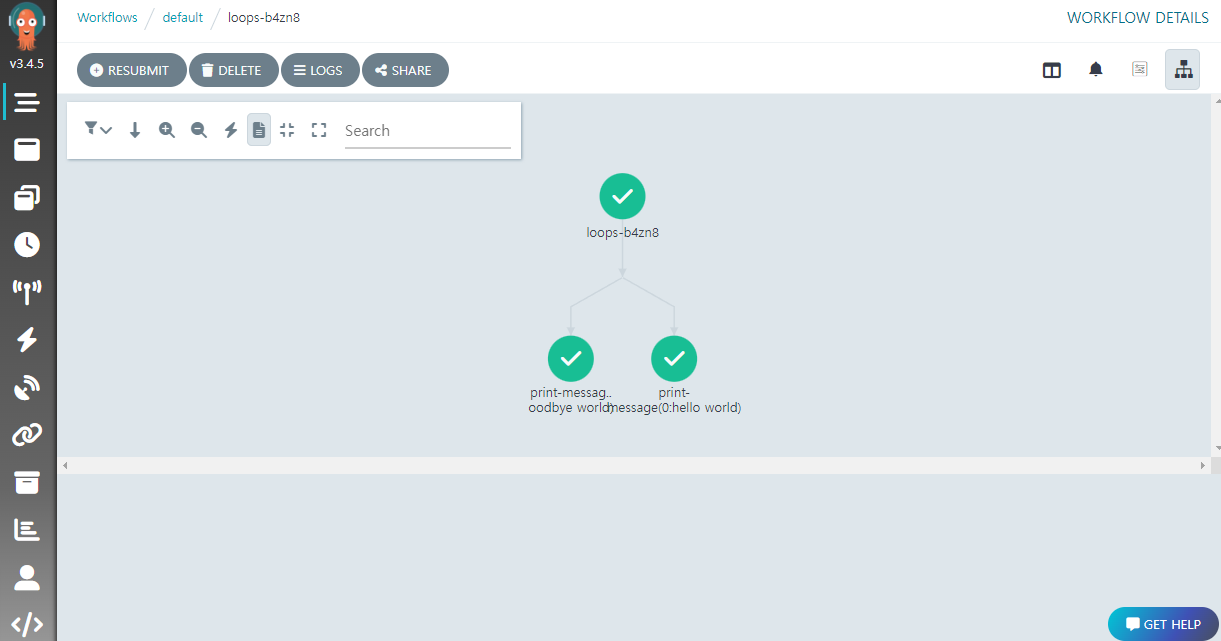
withItems 대신에 아래와 같이 withSequence 로 교체하면 인자 변경없이 반복 수행도 가능하다 (이 경우 {{item}} 형식으로 카운트를 참조할 수 있다).
# 반복 수행
withSequence:
count: "3"
JSON 객체 형태의 인자로 루프 이용
다음 예는 JSON Array 안에 { image: 'debian', tag: '9.1' } 형태의 객체로 항목을 기술하고 그것을 매개변수로 지정하여 템플릿을 호출하고 있다. 내용을 loops-param-argument.yaml 파일로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: loops-param-arg-
spec:
# 시작 템플릿
entrypoint: loop-param-arg-example
# 글로벌 매개변수의 인자
arguments:
parameters:
- name: os-list
# JSON Array 형식으로 컨테이너 이미지 이름과 태그 정보 기술
value: |
[
{ "image": "debian", "tag": "9.1" },
{ "image": "debian", "tag": "8.9" },
{ "image": "alpine", "tag": "3.6" },
{ "image": "ubuntu", "tag": "17.10" }
]
templates:
# OS 릴리즈 정보 출력 템플릿
- name: cat-os-release
# 입력 매개변수
inputs:
parameters:
- name: image
- name: tag
container:
# 호출측에서 인자로 건네진 이미지 정보로 컨테이너를 실행
image: "{{inputs.parameters.image}}:{{inputs.parameters.tag}}"
command: [cat]
args: [/etc/os-release]
# 템플릿 호출
- name: loop-param-arg-example
inputs:
parameters:
- name: os-list
steps:
- - name: test-linux
template: cat-os-release
arguments:
parameters:
- name: image
value: "{{item.image}}"
- name: tag
value: "{{item.tag}}"
withParam: "{{inputs.parameters.os-list}}"
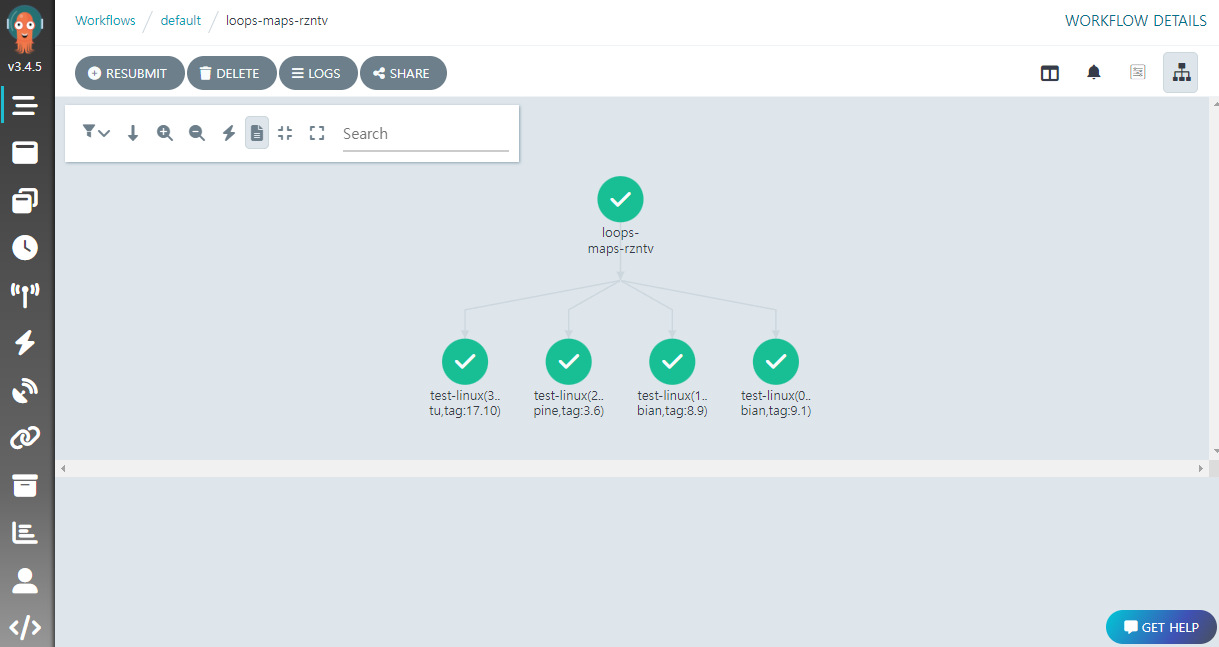
이 예제는 withItem 대신 withParam 을 사용하고 있는데, 이렇게 하면 개별 항목을 템플릿 호출에 하드코딩하지 않고 그것이 들어있는 매개변수를 지정할 수 있어 편리하다. 예제는 흥미롭게도 건네진 인자의 이미지로 컨테이너를 각각 실행하고 있는데, 다음처럼 실행하면,
argo submit --watch loops-param-argument.yaml
Argo Workflows UI 에서 다음처럼 루프를 통해 4 개 호출이 동시에 진행된 것을 알 수 있다.
DAG 에서 루프 이용
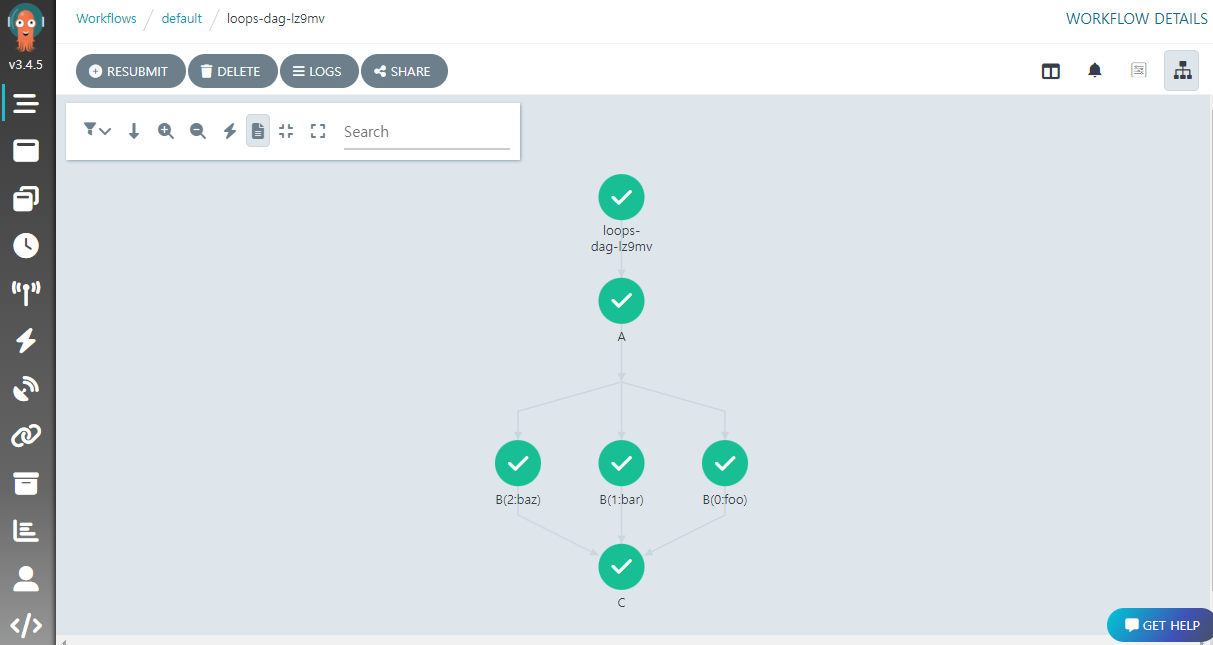
다음 예제는 앞서 소개한 DAG 에 루프를 이용한다. 태스크 B 에서 withItems 를 통한 루프 기능을 사용하고 있다. 이러한 경우 그 다음 태스크 C 에서 B 에 대한 의존성만 선언해주면, 태스크 B 의 모든 루프 호출이 완료된 후 C 가 실행된다.
다음 내용을 loops-dag.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: loops-dag-
spec:
# 시작 템플릿
entrypoint: loops-dag
templates:
- name: loops-dag
dag:
tasks:
- name: A
template: whalesay
arguments:
parameters:
- {name: message, value: A}
- name: B
depends: "A"
template: whalesay
arguments:
parameters:
- {name: message, value: "{{item}}"}
withItems:
- bar
- baz
- name: C
depends: "B"
template: whalesay
arguments:
parameters:
- {name: message, value: C}
- name: whalesay
inputs:
parameters:
- name: message
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
다음처럼 적용하면,
argo submit --watch loops-dag.yaml
루프를 통해 생성된 태스크 B 의 호출 3 개가 모두 완료된 후, C 가 실행되는 것을 확인할 수 있다.
고정된 많은 대상 파일에 대해 ETL 작업을 수행하고, 최종적으로 집계하는 경우 유용할 것이다.
아티팩트 워크플로우 예제
이 예제는 멀티 스텝 형태로, 첫 스텝 generate-artifact 에서 아티팩트를 생성하고, 다음 스텝 print-message 에서 생성된 아티팩트를 이용하도록 구현되어 있다. 내용을 artifact-passing.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: artifact-passing-
spec:
# 시작 템플릿
entrypoint: artifact-example
templates:
# 아티팩트 생성용 정의 템플릿
- name: whalesay
container:
image: docker/whalesay:latest
command: [sh, -c]
args: ["sleep 1; cowsay hello world | tee /tmp/hello_world.txt"]
# 출력으로 사용할 아티팩트
outputs:
artifacts:
# 생성된 /tmp/hello_world.txt 파일에서 hello-art 아티팩트를 생성
# (아티팩트는 파일뿐만 아니라 폴더 형태도 가능)
- name: hello-art # 출력 아티팩트 이름
path: /tmp/hello_world.txt # 출력 아티팩트 소스 파일
# 아티팩트 프린트용 정의 템플릿
- name: print-message
# 입력으로 사용할 아티팩트
inputs:
artifacts:
# 전달받은 아티팩트를 풀어서 /tmp/message 파일에 저장
- name: message # 입력 아티팩트 이름
path: /tmp/message # 입력 아티팩트 파일
container:
image: alpine:latest
# 아티팩트에서 풀린 파일 프린트
command: [sh, -c]
args: ["cat /tmp/message"]
# 멀티스텝 호출 템플릿
- name: artifact-example
steps:
# 1. 아트팩트 생성 호출
- - name: generate-artifact
template: whalesay
# 2. 아티팩트 프린트 호출
- - name: consume-artifact
template: print-message
arguments:
artifacts:
# 생성 호출에서 생성된 hello-art 아티팩트를 프린트 템플릿의 입력 아티팩트로 바인딩
- name: message
from: "{{steps.generate-artifact.outputs.artifacts.hello-art}}"
다음처럼 적용하면,
argo submit --watch artifact-passing.yaml
다음과 같은 출력이 나올 것이다.
Name: artifact-passing-j4rfp
Namespace: default
ServiceAccount: unset (will run with the default ServiceAccount)
Status: Succeeded
Conditions:
PodRunning False
Completed True
Created: Wed Mar 08 14:06:55 +0900 (31 seconds ago)
Started: Wed Mar 08 14:06:55 +0900 (31 seconds ago)
Finished: Wed Mar 08 14:07:26 +0900 (now)
Duration: 31 seconds
Progress: 2/2
ResourcesDuration: 12s*(1 cpu),12s*(100Mi memory)
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ artifact-passing-j4rfp artifact-example
├───✔ generate-artifact whalesay artifact-passing-j4rfp-whalesay-1776896446 5s
└───✔ consume-artifact print-message artifact-passing-j4rfp-print-message-4173331406 8s
생성 작업의 출력이 아티팩트 저장소인 MinIO 에 올라가고, 프린트 작업은 입력 아티팩트를 MinIO 에서 내려 받아서 이용하는 식이다. UI 에서 살펴보면 생성된 아티팩트 hello-art.tgz 를 확인할 수 있다.
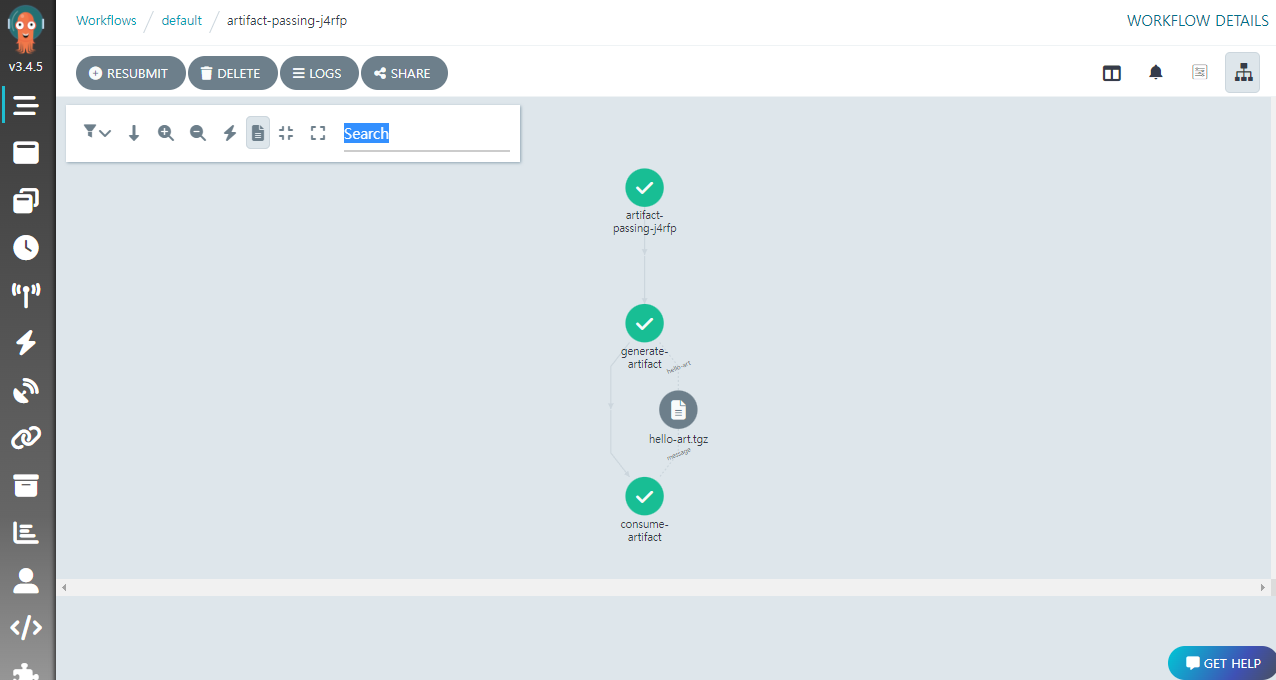
아티팩트는 기본적으로
tar+gzip파일로 압축되는데, 필요에 따라 압축 설정을 바꿀 수 있다.
지금까지 Argo Event 와 Workflows 의 기본적인 동작을 확인하였다. 이제 두 서비스를 결합하여 기본적인 ETL 을 진행하는 예를 살펴보겠다.
ETL 맛보기
일반적인 ETL 예제에서는 로컬에 있는 원본 파일을 불러와 가공하는 식으로 진행하지만, 쿠버네티스 클러스터에서는 다양한 컨테이너가 활용되기에 특정 노드에 존재하는 파일을 이용하는 방식은 적합하지 않다. 따라서 MinIO 같은 스토리지 서비스가 활용되어야 한다.
이 예제는 MinIO 에 ETL 대상 파일이 올라온 경우, 그것을 Argo Events 로 감지하고 Argo Workflows 를 통해 ETL 하는 것을 목표로 한다.
MinIO 는 AWS S3 와 완전 호환되기에 이 예제를 S3 에 적용하는 것도 어렵지 않을 것이다.
예제를 위한 컨테이너 이미지 만들기
여기서 설명하는 내용은 향후 사용자의 독자적인 컨테이너 이미지가 필요한 경우를 위해서이다. 이 글의 예제를 따라하기 위해서라면 이미지를 별도로 만들 필요없이, 필자가 미리 만들어둔 이미지
haje01/argo-etl:0.1.5를 이용하면 된다.
예제의 ETL 코드는 파이썬으로 작성될 것인데, MinIO 에서 파일을 가져오기 위해 minio 패키지의 설치가 필요하다. 다음과 같은 내용으로 Dockerfile 을 저장한다.
FROM python:3.10-bullseye
RUN pip install --no-cache-dir minio
RUN pip install --no-cache-dir pyarrow
RUN pip install --no-cache-dir pandas
RUN pip install --no-cache-dir boto3
RUN pip install --no-cache-dir protobuf
RUN pip install --no-cache-dir grpcio
RUN pip install --no-cache-dir pyyaml
이것을 빌드하고 도커 레지스트리에 등록하기 위해, 아래와 같은 내용으로 build.sh 파일을 저장한다.
USERNAME=<Docker 허브 계정>
IMAGE=argo-etl
VERSION=0.1.5
docker build -t $USERNAME/$IMAGE:latest -f Dockerfile .
docker tag $USERNAME/$IMAGE:latest $USERNAME/$IMAGE:$VERSION
docker login -u $USERNAME
docker push $USERNAME/$IMAGE:latest
docker push $USERNAME/$IMAGE:$VERSION
다음처럼 실행하면 이미지 빌드 후 도커 허브로 푸쉬한다 (도커허브 계정으로 로그인 필요)
sh build_image.sh
ETL 코드 작성
전체적인 흐름을 파악하는 것이 목적이기에 ETL 코드는 일단 MinIO 에 올라온 CSV 파일을 JSON 으로 변환하여 저장하는 정도로 하겠다.
다음 파이썬 코드를 etl.py 로 저장한다.
import os
import sys
import csv
import json
from minio import Minio
# MinIO 접속 정보
MINIO_ENDPOINT = "minio:9000"
MINIO_USER = os.environ['MINIO_USER']
MINIO_PASSWD = os.environ['MINIO_PASSWD']
# MinIO 오브젝트 정보
BUCKET = sys.argv[1]
KEY = sys.argv[2]
IN_FILE = f'/tmp/{os.path.basename(KEY)}'
OUT_FILE = '/tmp/output.json'
NAMES = ['no', 'name', 'score']
# MinIO 에서 입력 오브젝트 내려받기
client = Minio(MINIO_ENDPOINT, access_key=MINIO_USER, secret_key=MINIO_PASSWD, secure=False)
client.fget_object(BUCKET, KEY, IN_FILE)
# CSV 를 읽어 JSON 으로 변환
with open(IN_FILE, 'r') as csv_file:
reader = csv.reader(csv_file)
with open(OUT_FILE, 'w') as json_file:
for cnt, row in enumerate(reader):
data = dict(zip(NAMES, row))
json_file.write(json.dumps(data))
print(f'Processed {cnt + 1} lines.')
MinIO 의 접속 정보를 환경 변수에서 얻은 뒤 대상 객체를 내려받아 JSON 으로 변환 후 저장하고 있다.
이 코드를 쿠버네티스 클러스터에서 사용할 수 있도록, 다음과 같이 ConfigMap 을 만든다.
kubectl create configmap etl-code --from-file=etl.py
ConfigMap 으로 만들어 두면 클러스터 내 임의 파드에서 코드를 불러올 수 있다. 코드 수정을 적용하려면 기존 ConfigMap 리소스를 삭제하고 다시 만들어 주어야 한다.
여기에서는 간단히 설명하기 위해 코드를 ConfigMap 에 담아서 실행하고 있지만, 실제 서비스 용으로는 문제가 많은 방법이다. 바람직한 것은 실행할 컨테이너 이미지에 코드를 포함시키는 것인데, 관련 내용은 이 글의 후속편 격인 Argo 기반 ETL 코드에 Skaffold 적용하기 를 참고하기 바란다.
워크플로우와 Secret 만들기
MinIO 이벤트 발생시 위 코드를 Argo Workflows 를 통해 실행하려면 워크플로우 정의가 필요하다. 앞서 소개한 Argo Workflows 의 컨테이너 템플릿 형식으로 작성한다.
다음 내용을 etl-workflow.yaml 로 저장한다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: etl- # 워크플로우 생성 이름
spec:
# 시작 템플릿
entrypoint: etl
# 인자값. 버킷과 키 (이벤트가 발생될 때 건네진다.)
arguments:
parameters:
- name: bucket
- name: key
# ETL 템플릿을 정의
templates:
- name: etl
inputs:
# 매개변수
parameters:
- name: bucket
- name: key
container:
image: haje01/argo-etl:0.1.5
command: [python]
args: ['/code/etl.py', '{{inputs.parameters.bucket}}', '{{inputs.parameters.key}}']
# MinIO 사용자 및 암호를 Se로 전달
env:
- name: MINIO_USER
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-user
- name: MINIO_PASSWD
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-password
# 코드 볼륨을 컨테이너에 마운트
volumeMounts:
- name: etl-vol
mountPath: /code
volumes:
# ConfigMap 에서 코드 볼륨 생성
- name: etl-vol
configMap:
name: etl-code
outputs:
# 결과 파일에서 출력 아티팩트 생성
artifacts:
- name: output-art # 출력 아티팩트 이름
path: /tmp/output.json # 출력 아티팩트 소스 파일
etl.py 코드를 포함한 ConfigMap 을 컨테이너의 폴더로 마운트하고, 파이썬을 통해 실행하고 있다. 이 때 Serect 리소스를 통해 MinIO 접속 정보를 얻어 환경 변수로 전달하고 있는데, 이를 위한 Secret 은 아래와 같이 만들어 준다.
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: minio
type: Opaque
data:
accessKey: YWRtaW4=
secretKey: YWRtaW5kamVtYWxz
EOF
워크플로우 파일은 사용자가 직접 실행하는 것이 아니고, 이벤트가 발생하였을 때 센서를 통해 트리거링 된다. 클러스터에서 불러올 수 있게 ConfigMap 을 만든다.
kubectl create configmap etl-workflow --from-file=etl-workflow.yaml
마찬가지로 워크플로우를 변경하려면 ConfigMap 을 삭제하고 다시 만들어 주어야 한다.
워크플로우 용 Service Account 만들기
Argo Events 는 Argo Workflows 타입의 트리거를 이용해 워크플로우를 쿠버네티스에 띄울 수 있다. 그러나, 이 작업은 쿠버네티스 클러스터 상에서 다양한 리소스를 다루어야 하기에, 관련 권한이 있는 별도의 서비스 어카운트가 필요하다.
다음과 같이 실행하여 워크플로우 실행 권한을 가진 operate-workflow-sa 서비스 어카운트가 생성하자.
kubectl apply -f - <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: default
name: operate-workflow-sa
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: operate-workflow-role
namespace: default
rules:
- apiGroups:
- argoproj.io
verbs:
- "*"
resources:
- workflows
- workflowtemplates
- cronworkflows
- clusterworkflowtemplates
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: operate-workflow-role-binding
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: operate-workflow-role
subjects:
- kind: ServiceAccount
name: operate-workflow-sa
EOF
MinIO 이벤트 소스 생성
다음으로 MinIO 에 파일이 생성되는 이벤트를 위한 이벤트 소스를 만들겠다. 이를 위해 먼저 MinIO UI 페이지로 가서, etlproj 라는 이름으로 지금부터 사용할 버킷을 만들어 둔다.
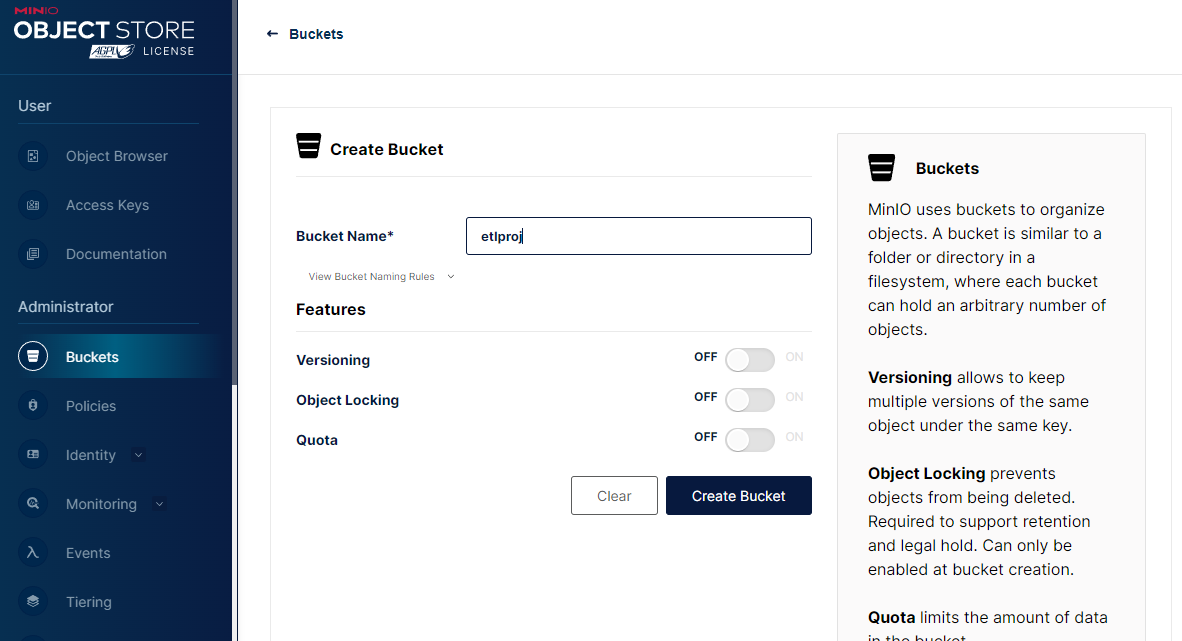
이제 이 버킷 및 접두어 (Prefix) 에 대해 특정 이벤트를 감지할 수 있도록 이벤트 소스를 기술한다. 다음 내용을 etl-evtsrc.yaml 로 저장한다.
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: etl
spec:
# MinIO 타입
minio:
# Put 이벤트
put:
bucket:
# 대상 버킷 이름
name: etlproj
# 서비스 엔드포인트
endpoint: minio:9000
# 구독할 MinIO 이벤트 리스트
# (참고 https://docs.minio.io/docs/minio-bucket-notification-guide.html)
events:
- s3:ObjectCreated:Put
# input 접두어 아래 .csv 로 끝나는 파일만 대상
filter:
prefix: "input/"
suffix: ".csv"
# 커넥션 타입
insecure: true
# MinIO 키가 있는 Secret 리소스 정보
accessKey:
name: minio
key: root-user
secretKey:
name: minio
key: root-password
etlproj 버킷 아래 input/*.csv 오브젝트에 대한 생성 (put) 이벤트를 감지하도록 하였다. 다음처럼 적용하자
kubectl create -f etl-evtsrc.yaml
MinIO 센서 생성
다음은 위에서 정의한 이벤트가 발생했을 때 사용 (Consume) 하는 센서를 만들겠다. 아래 내용을 etl-sensor.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: etl
spec:
template:
# 앞서 만들어둔 Service Account 이용
serviceAccountName: operate-workflow-sa
container:
# 워크플로우 볼륨을 컨테이너에 마운트
volumeMounts:
- name: etl-workflow-vol
mountPath: /workflow
# ConfigMap 에서 워크플로우 볼륨 생성
volumes:
- name: etl-workflow-vol
configMap:
name: etl-workflow
# 의존하는 이벤트
dependencies:
- name: evt-dep
eventSourceName: etl
eventName: put
triggers:
- template:
name: etl-workflow-trigger
k8s:
# 컨테이너에 마운트된 ETL 워크플로우 실행 (생성)
operation: create
source:
file:
path: /workflow/etl-workflow.yaml
# 매개변수. MinIO 이벤트 정보 (Notification) 를 읽어 워크플로우의 인자값을 덮어 씀
parameters:
- src:
dependencyName: evt-dep
dataKey: notification.0.s3.bucket.name
dest: spec.arguments.parameters.0.value
- src:
dependencyName: evt-dep
dataKey: notification.0.s3.object.key
dest: spec.arguments.parameters.1.value
사실 예제처럼 하나의 템플릿으로 구성된 워크플로우의 경우는, 굳이 Workflow 를 사용하지 않고 센서에서 바로 Pod 를 호출해 ETL 을 해도 된다.
앞서 만든 etl EventSource 의 조건에 맞는 MinIO 이벤트가 발생하면, 그 정보 (버킷 이름과 오브젝트 키) 를 인자값으로 하여 쿠버네티스에서 워크플로우 객체를 생성, 실행하게 된다.
다음처럼 적용하면 etl 이라는 이름의 Sensor 가 만들어진다.
kubectl apply -f etl-sensor.yaml
테스트하기
이제 대상 MinIO 버킷에 파일을 업로드하고, 그것이 워크플로우를 통해 잘 처리되는지 확인해보자. 먼저 다음과 같은 내용의 test.csv 파일을 로컬에 만든다.
1,aaa,100
2,bbb,80
3,ccc,90
다음은 MinIO UI 의 Object Browser 탭의 etlproj 버킷 에서 Create new path 를 클릭하여 input 폴더 패스를 만들어 준다.
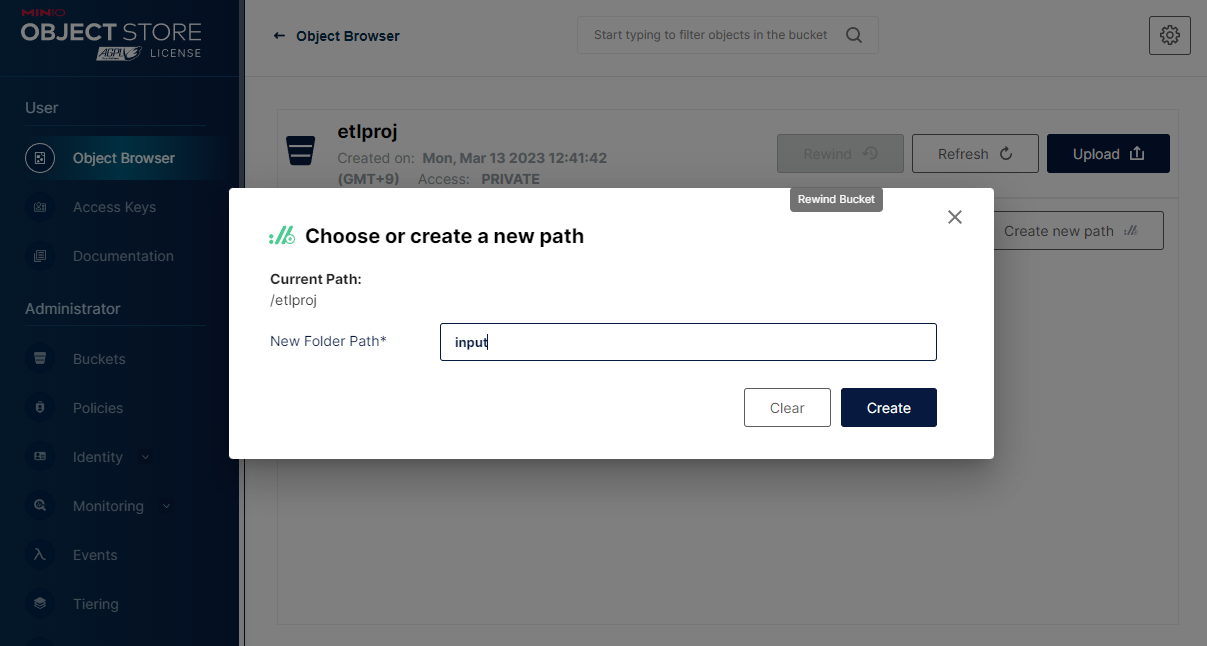
다음으로 Upload / Upload File 를 클릭하고 대화창에서 로컬 파일을 선택하여 업로드한다.
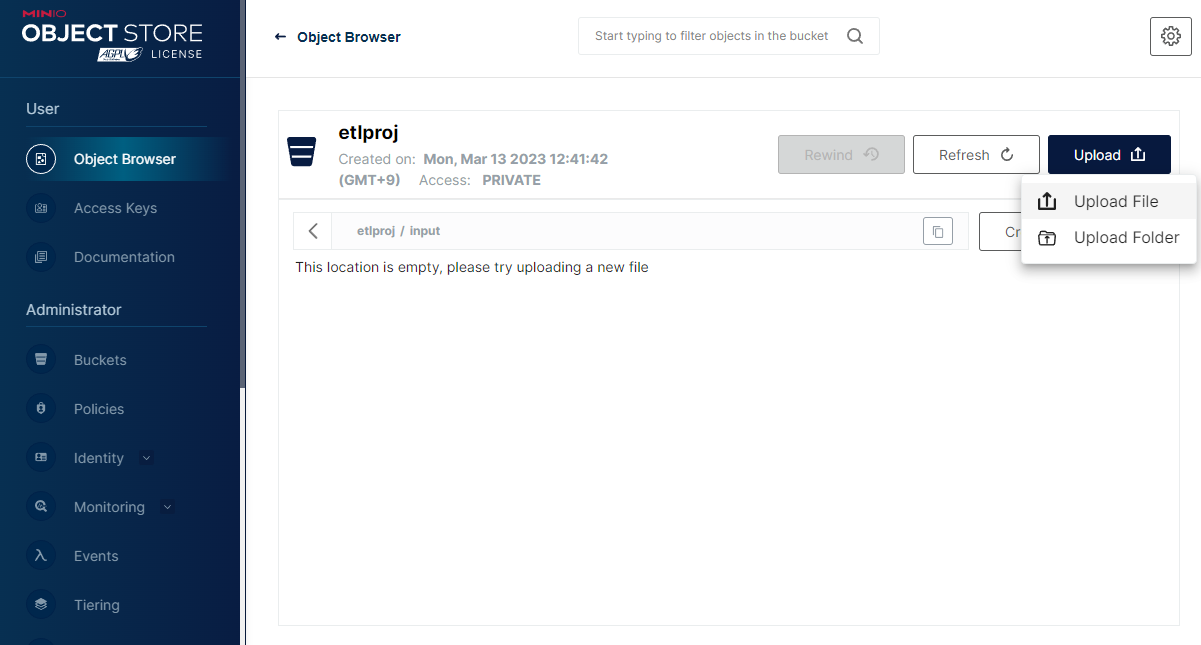
MinIO 는 AWS S3 와 호환이 되기에, AWS CLI 툴을 이용해서 업로드할 수도 있다. 다음 웹페이지를 참고하자. https://min.io/docs/minio/linux/integrations/aws-cli-with-minio.html
파일이 정상적으로 올라갔으면, Argo Workflows UI 에서 다음처럼 ETL 워크플로우가 생성되고, ETL 코드가 완료되면 아티팩트가 생성된 것을 확인할 수 있다.
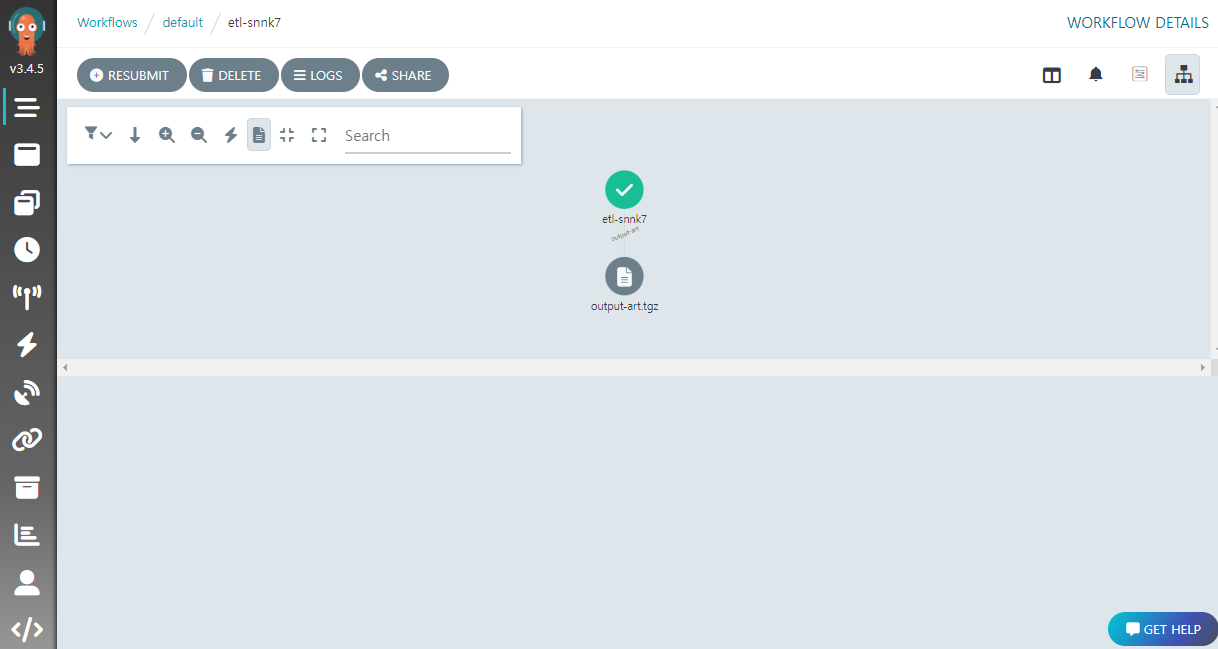
MinIO UI 의 artifact 버킷에서 ETL 결과 파일을 확인하고 내려받을 수 있다.
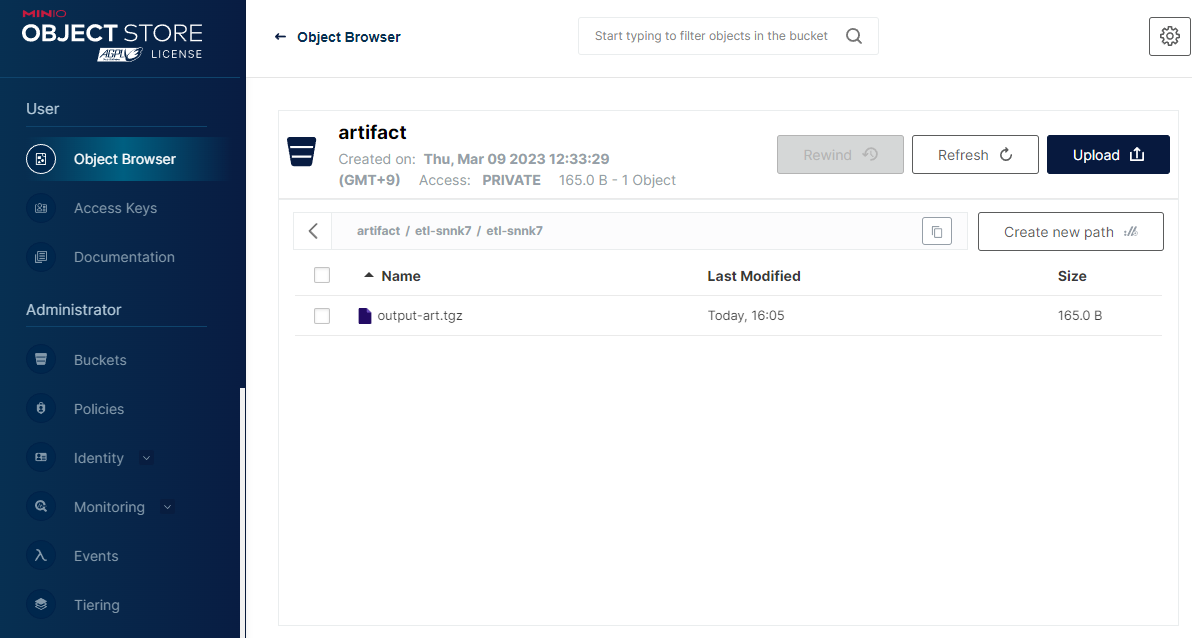
결과 파일의 내용은 다음과 같은 JSON Lines 파일이다.
{"no": "1", "name": "aaa", "score": "100"}
{"no": "2", "name": "bbb", "score": "80"}
{"no": "3", "name": "ccc", "score": "90"}
만약 워크플로우가 생성되지 않거나, 생성되었지만 잘 동작하지 않는다면
kubectl의describe및logs를 통해서 이벤트 소스, 센서 그리고 워크플로우 파드의 상태를 확인해보자.
파케이 (Parquet) 파일로 저장
실무에서 ETL 결과물은 저장 및 검색 효율성을 위해 Parquet 나 ORC 같은 컬럼형 포맷을 많이 이용한다. 여기서는 기존 JSON 결과물을 Parquet 로 저장하도록 ETL 코드를 개량할 것인데, 이를 위해 Pandas 를 사용하겠다.
기존 etl.py 코드를 다음처럼 변경하여 저장한다.
import os
import sys
import csv
import json
from minio import Minio
import pandas as pd
# MinIO 접속 정보
MINIO_ENDPOINT = "minio:9000"
MINIO_USER = os.environ['MINIO_USER']
MINIO_PASSWD = os.environ['MINIO_PASSWD']
# MinIO 오브젝트 정보
BUCKET = sys.argv[1]
KEY = sys.argv[2]
IN_FILE = f'/tmp/{os.path.basename(KEY)}'
OUT_FILE = '/tmp/output.parquet'
NAMES = ['no', 'name', 'score']
# MinIO 에서 입력 오브젝트 내려받기
client = Minio(MINIO_ENDPOINT, access_key=MINIO_USER, secret_key=MINIO_PASSWD, secure=False)
client.fget_object(BUCKET, KEY, IN_FILE)
# Pandas 를 통해 CSV 를 읽고, Parquet 로 저장
df = pd.read_csv(IN_FILE, names=NAMES)
df.to_parquet(OUT_FILE)
print(f'Processed {len(df)} lines.')
새 코드를 반영하기 위해 기존 ConfigMap 삭제 후 다시 생성한다.
kubectl delete configmap etl-code
kubectl create configmap etl-code --from-file=etl.py
--from-file을 이용해 생성한 ConfigMap 의 경우, 아래와 같은 방식의replace명령으로도 교체 가능하다.kubectl create configmap etl-code --from-file=etl.py -o yaml --dry-run=client | kubectl replace -f -
바뀐 ETL 코드를 위해 워크플로우도 수정이 필요하다. 기존 etl-workflow.yaml 파일을 아래의 내용으로 교체하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: etl- # 워크플로우 생성 이름
spec:
# 시작 템플릿
entrypoint: etl
# 인자값. 버킷과 키 (이벤트가 발생될 때 건네진다.)
arguments:
parameters:
- name: bucket
- name: key
# ETL 템플릿을 정의
templates:
- name: etl
inputs:
# 매개변수
parameters:
- name: bucket
- name: key
container:
image: haje01/argo-etl:0.1.5
command: [python]
args: ['/code/etl.py', '{{inputs.parameters.bucket}}', '{{inputs.parameters.key}}']
# MinIO 사용자 및 암호를 Se로 전달
env:
- name: MINIO_USER
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-user
- name: MINIO_PASSWD
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-password
# 코드 볼륨을 컨테이너에 마운트
volumeMounts:
- name: etl-vol
mountPath: /code
volumes:
# ConfigMap 에서 코드 볼륨 생성
- name: etl-vol
configMap:
name: etl-code
outputs:
# 결과 파일에서 출력 아티팩트 생성
artifacts:
- name: output-art # 출력 아티팩트 이름
path: /tmp/output.parquet # 출력 아티팩트 소스 파일
archive: {} # 파케이 파일의 경우 별도 압축하지 않음
출력 아티팩트가 Parquet 형식으로 바뀌었고, 별도 압축을 하지 않도록 하였다.
새 내용을 반영하기 위해 기존 ConfigMap 을 삭제 후 다시 생성한다.
kubectl delete configmap etl-workflow
kubectl create configmap etl-workflow --from-file=etl-workflow.yaml
이제 다시 test.csv 를 MinIO UI 에서 Upload 하면, 새로운 워크플로우가 실행되고 그 결과물 output.parquet 을 확인할 수 있다.
이 파일을 내려받아 파이썬으로 읽어보면, 다음과 같이 Parquet 형식임을 알 수 있다.
>>> import pandas as pd
>>> df = pd.read_parquet('output.parquet')
>>> df
no name score
0 1 aaa 100
1 2 bbb 80
2 3 ccc 90
다수의 원본 파일 ETL 및 집계
지금까지는 하나의 원본 CSV 에 대해서 진행하였다. 이제 원본 파일이 여러개 있는 경우에 대해 알아보겠다.
준비 작업
여기에서는 날짜별 폴더에 그날의 테스트 점수가 여러 파일로 나누어 올라오는 경우를 생각해보자. 먼저, 테스트를 위해 로컬에 20230414 폴더를 만들고 거기에 다음과 같은 CSV 파일들을 생성한다.
1.csv
1,aaa,70
2,bbb,80
3,ccc,90
2.csv
4,ddd,80
5,eee,70
6,fff,60
3.csv
7,ggg,50
8,hhh,90
9,iii,100
지금까지 예제에서 대상 CSV 파일이 동시에 여럿 올라오면 어떻게 될까? 문제가 없다면 각 파일을 Argo Events 가 감지하고, 각각에 대해서 워크플로우가 실행되어야 할 것이다.
MinIO UI 에서 Upload File 대신 Upload Folder 를 클릭하고, 만들어둔 20230414 폴더를 지정하여 업로드 해보면, 3 개 파일에 대해서 각각 동시에 워크플로우가 기동하고, 버킷의 etlproj/output 폴더에서 결과 파일을 확인할 수 있다.
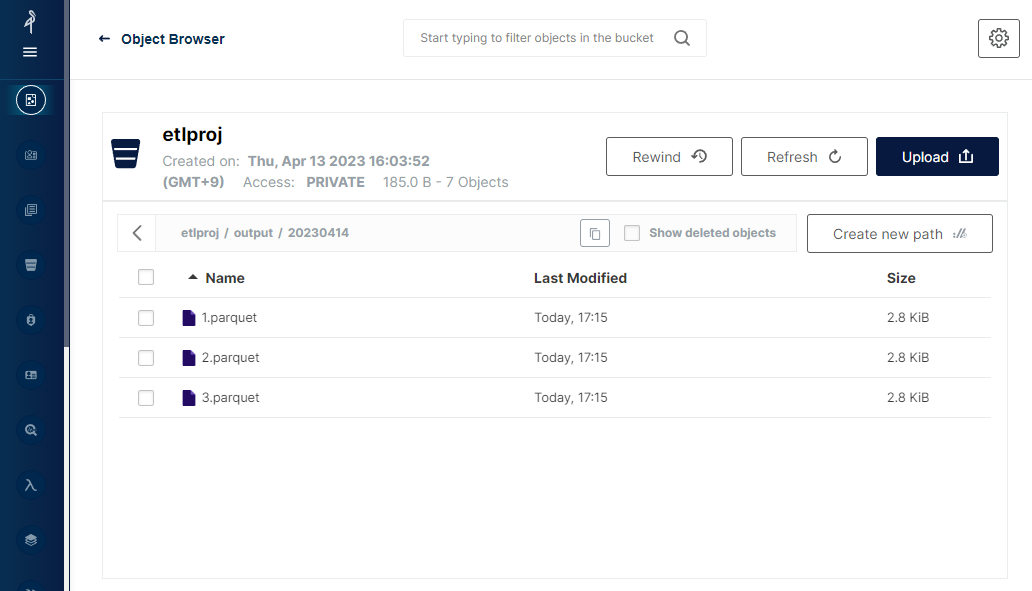
다음 진행을 위해서 Argo CLI 가 설치된 컨테이너 이미지가 필요하다.
아래 설명하는 내용은 향후 사용자의 독자적인 컨테이너 이미지가 필요한 경우를 위해서이다. 이 글의 예제를 따라하기 위해서라면 이미지를 별도로 만들 필요없이, 필자가 미리 만들어둔 이미지
haje01/argo-cli:0.0.2을 이용하면 된다.
다음처럼 Dockerfile.argocli 파일을 만들고,
FROM alpine:latest
RUN apk add --no-cache curl gzip jq
RUN curl -sLO https://github.com/argoproj/argo-workflows/releases/download/v3.4.5/argo-linux-amd64.gz
RUN gunzip argo-linux-amd64.gz
RUN chmod +x argo-linux-amd64
RUN mv ./argo-linux-amd64 /usr/local/bin/argo
ENTRYPOINT ["/bin/sh"]
빌드 스크립트 build-argocli.sh 도 만든다.
USERNAME=<Docker 허브 계정>
IMAGE=argo-cli
VERSION=0.0.2
docker build -t $USERNAME/$IMAGE:latest -f Dockerfile.argocli .
docker tag $USERNAME/$IMAGE:latest $USERNAME/$IMAGE:$VERSION
docker login -u $USERNAME
docker push $USERNAME/$IMAGE:latest
docker push $USERNAME/$IMAGE:$VERSION
다음처럼 실행하면 이미지 빌드 후 도커 허브로 푸쉬한다 (도커허브 계정으로 로그인 필요)
sh build-argocli.sh
불특정한 개수의 원본 파일 집계 방식
이제 모든 ETL 결과를 모아 집계하는 과정에 대해 알아보자.
만약 원본 파일의 개수가 정해져 있는 경우 앞에서 설명한 DAG 템플릿을 이용하여 간단히 최종 집계를 기술할 수 있다. 그렇지만, 실제 현업에서는 원본 파일의 수가 정해져 있지 않은 때가 많기에, 여기서는 그런 경우를 가정하겠다.
예를 들어 앞의 예제에서 원본 파일의 개수가 변할 수 있다고 가정하고, ETL 을 수행한 뒤 그날의 최고 점수자를 찾으려면 어떻게 하면 될까?
다양한 방법으로 구현이 가능하겠으나 필자는 다음과 같이 접근해보겠다:
- 각 원본 파일의 ETL 결과를 MinIO
etlproj버킷의 결과 폴더output아래 날짜 폴더20230414를 만들어 올림 - Argo Events 는 결과 폴더
output을 모니터링하다, 새 ETL 결과 파일이 생성되면 집계 워크플로우를 실행 - 집계 워크플로우에서는
- 진행 중인 선행 집계 워크플로우가 있으면 취소 (동시 집계 방지)
- 적당한 지연 시간 (여기서는 10초) 을 기다린 후,
output/20230414폴더 내 모든 ETL 결과 파일을 내려 받아 집계 수행 후 결과 업로드
설명을 위해 먼저 용어를 소개하겠다. 집계가 완료된 후 새로운 원본 파일이 올라오는 경우 새 집계가 선행 집계의 결과를 덮어쓰게 되는데, 이런 경우 선행 집계를 낭비 집계 라 하겠다. 낭비 집계가 발생하면 그것을 위한 컴퓨팅 리소스는 낭비된 셈이나 큰 문제는 아니다.
동시 집계 란 하나의 ETL 이 끝나 집계가 진행중인데, 또 다른 ETL 이 완료되어 새 집계가 시작되는 것을 말한다. 이런 경우도 선행 집계는 낭비가 되며, 집계 결과 파일에 오류가 생기는 문제도 우려가 된다. 이에 동시 집계를 방지하기 위해 새 집계가 선행 집계를 삭제하도록 하였다.
지연 시간 은 실제 집계를 진행하기 전에 대기하는 시간인데, 또 다른 원본 파일이 금방 올라올 수도 있기 때문에 여유를 두는 것이다. 원본 파일이 꾸준히 올라오는 경우 지연 시간이 너무 짧으면 낭비 집계가 발생하기 쉽고, 너무 길면 집계의 실시간성이 떨어질 것 이다. 따라서 상황에 맞게 지연 시간을 정해야 한다.
적당한 지연 시간을 주면 연이어 새 원본 파일이 올라오는 경우, 실제 집계에 들어가기 전에 선행 집계를 취소할 수 있어 컴퓨팅 리소스의 낭비를 줄일 수 있다.
ETL 코드, 워크플로우, 이벤트 소스 작업
먼저 결과 파일을 MinIO 의 날짜 폴더로 올리도록, 아래처럼 기존 etl.py 파일을 수정한다.
import os
import sys
import csv
import json
import time
from minio import Minio
import pandas as pd
# MinIO 접속 정보
MINIO_ENDPOINT = "minio:9000"
MINIO_USER = os.environ['MINIO_USER']
MINIO_PASSWD = os.environ['MINIO_PASSWD']
# MinIO 오브젝트 정보
BUCKET = sys.argv[1]
KEY = sys.argv[2]
NAME_ONLY = os.path.splitext(os.path.basename(KEY))[0]
NAME_NO = int(NAME_ONLY)
DATE = KEY.split('/')[-2]
IN_FILE = f'/tmp/{os.path.basename(KEY)}'
OUT_FILE = '/tmp/output.parquet'
NAMES = ['no', 'name', 'score']
# 파일 이름 x 10 초 만큼 대기
print(f"Sleep for {NAME_NO * 3} seconds")
time.sleep(NAME_NO * 10)
# MinIO 에서 입력 오브젝트 내려받기
client = Minio(MINIO_ENDPOINT, access_key=MINIO_USER, secret_key=MINIO_PASSWD, secure=False)
client.fget_object(BUCKET, KEY, IN_FILE)
# Pandas 를 통해 CSV 를 읽고, Parquet 로 저장
df = pd.read_csv(IN_FILE, names=NAMES)
df.to_parquet(OUT_FILE)
print(f'Processed {len(df)} lines.')
# MinIO 상 결과 폴더에 업로드
UPKEY = f'output/{DATE}/{NAME_ONLY}.parquet'
client.fput_object(BUCKET, UPKEY, OUT_FILE)
print(f"Uploaded to '{BUCKET}/{UPKEY}'")
위의 코드에서 파일 이름의 숫자만큼 지연을 주는 부분이 있는데, 이것은 파일이 조금씩 시간차를 두고 올라오는 것을 흉내내기 위함이다. 예를 들어 3.csv 는 3 x 10 초 만큼 지연되어 처리된다.
기존 ConfigMap 을 지우고 새로 생성한다.
kubectl delete configmap etl-code
kubectl create configmap etl-code --from-file=etl.py
ETL 과정에서 결과를 직접 MinIO 에 올리고 있기에 워크플로우에서 출력 아티팩트는 지정하지 않는다. etl-workflow.yaml 을 다음처럼 수정한다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: etl- # 워크플로우 생성 이름
spec:
# 시작 템플릿
entrypoint: etl
# 인자값. 버킷과 키 (이벤트가 발생될 때 건네진다.)
arguments:
parameters:
- name: bucket
- name: key
# ETL 템플릿을 정의
templates:
- name: etl
inputs:
# 매개변수
parameters:
- name: bucket
- name: key
container:
image: haje01/argo-etl:0.1.5
command: [python]
args: ['/code/etl.py', '{{inputs.parameters.bucket}}', '{{inputs.parameters.key}}']
# MinIO 사용자 및 암호를 Se로 전달
env:
- name: MINIO_USER
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-user
- name: MINIO_PASSWD
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-password
# 코드 볼륨을 컨테이너에 마운트
volumeMounts:
- name: etl-vol
mountPath: /code
volumes:
# ConfigMap 에서 코드 볼륨 생성
- name: etl-vol
configMap:
name: etl-code
새 내용을 반영하기 위해 기존 ConfigMap 을 삭제 후 다시 생성한다.
kubectl delete configmap etl-workflow
kubectl create configmap etl-workflow --from-file=etl-workflow.yaml
집계 코드 만들기
집계 코드에서는 각 ETL 결과를 취합하고, 점수 열이 가장 높은 행을 텍스트로 저장한다. 아래 내용을 agg.py 로 저장하자.
import os
import sys
import time
from minio import Minio
import pandas as pd
MINIO_ENDPOINT = "minio:9000"
MINIO_USER = os.environ['MINIO_USER']
MINIO_PASSWD = os.environ['MINIO_PASSWD']
# MinIO 오브젝트 정보
BUCKET = sys.argv[1]
KEY = sys.argv[2]
NAME_ONLY = os.path.splitext(os.path.basename(KEY))[0]
DATE = KEY.split('/')[-2]
PREFIX = f'output/{DATE}'
OUT_FILE = 'agg.txt'
OUT_PATH = f'/tmp/{OUT_FILE}'
NAMES = ['no', 'name', 'score']
dfs = []
# 대상 MinIO 버킷에서 모든 결과 파일 내려받고, Pandas 로 읽기
client = Minio(MINIO_ENDPOINT, access_key=MINIO_USER, secret_key=MINIO_PASSWD, secure=False)
objects = client.list_objects(BUCKET, prefix=PREFIX, recursive=True)
for obj in objects:
objname = obj.object_name
# 집계 파일 제외
if not objname.endswith('.parquet'):
continue
local_path = os.path.join('/tmp', objname)
print(f"Download {BUCKET}/{objname} to '{local_path}'")
client.fget_object(BUCKET, objname, local_path)
# Pandas 를 통해 Parquet 읽기
df = pd.read_parquet(local_path)
dfs.append(df)
# 결과 Dataframe 병합
print("Merge dataframes.")
mdf = pd.concat(dfs).reset_index()
mi = mdf['score'].idxmax()
mrow = mdf.loc[mi].to_string()
with open(OUT_PATH, 'wt') as f:
f.write(mrow)
print(f'Found max result: {mrow}')
# MinIO 결과 폴더에 업로드
UPKEY = f'output/{DATE}/{OUT_FILE}'
client.fput_object(BUCKET, UPKEY, OUT_PATH)
print(f"Uploaded to '{BUCKET}/{UPKEY}")
코드를 ConfigMap 으로 만든다.
kubectl create configmap agg-code --from-file=agg.py
집계를 위한 EventSource 와 워크플로우
이제 집계를 위한 이벤트 소스를 만들어야 하는데, ETL 결과 폴더를 모니터링하는 역할이다. 아래 내용을 agg-evtsrc.yaml 파일로 저장한다.
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: agg
spec:
# MinIO 타입
minio:
# Put 이벤트
put:
bucket:
# 대상 버킷 이름
name: etlproj
# 서비스 엔드포인트
endpoint: minio:9000
# 구독할 MinIO 이벤트 리스트
# (참고 https://docs.minio.io/docs/minio-bucket-notification-guide.html)
events:
- s3:ObjectCreated:Put
# output 접두어 아래 .parquet 로 끝나는 파일만 대상
filter:
prefix: "output/"
suffix: ".parquet"
# 커넥션 타입
insecure: true
# MinIO 키가 있는 Secret 리소스 정보
accessKey:
name: minio
key: root-user
secretKey:
name: minio
key: root-password
ETL 결과 파일 모니터링을 위해 대상 폴더는 input 이 아닌 output 으로, 확장자는 .csv 가 아닌 .parquet 를 대상으로 하고 있다.
다음은 집계를 위한 워크플로우가 필요하다. 앞에서 설명한 것처럼 스텝스 형식으로 먼저 선행 워크플로우가 있으면 그것을 취소하고, 잠시 대기 후 새 집게를 시작한다. 워크플로우 제거를 위해 앞서 만든 argo-cli 이미지를 사용한다.
아래 내용을 agg-workflow.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: agg- # 워크플로우 생성 이름
spec:
serviceAccountName: operate-workflow-sa
# 시작 템플릿
entrypoint: check-wait-agg
# 인자값. 버킷과 키 (이벤트가 발생될 때 건네진다.)
arguments:
parameters:
- name: bucket
- name: key
templates:
# 이전 집계가 있으면 제거
- name: check-prev
container:
image: haje01/argo-cli:0.0.2
command:
- /bin/sh
- -c
- >
argo list --prefix agg- --status Running -o json | sed '/^No workflows/d' | jq '.[] | select(.spec.arguments.parameters[] | select(.name == "key" and .value != "{{workflow.parameters.key}}" )) | .metadata.name' -r | xargs -I {} argo terminate {}
# 대기
- name: delay
suspend:
duration: "10s"
# 집계
- name: agg
container:
image: haje01/argo-etl:0.1.5
command: [python]
args: ['/code/agg.py', '{{workflow.parameters.bucket}}', '{{workflow.parameters.key}}']
# MinIO 사용자 및 암호를 Se로 전달
env:
- name: MINIO_USER
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-user
- name: MINIO_PASSWD
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: minio
key: root-password
# 코드 볼륨을 컨테이너에 마운트
volumeMounts:
- name: agg-vol
mountPath: /code
volumes:
# ConfigMap 에서 코드 볼륨 생성
- name: agg-vol
configMap:
name: agg-code
# 템플릿 호출
- name: check-wait-agg
steps:
- - name: check
template: check-prev
- - name: wait
template: delay
- - name: agg
template: agg
위 파일에서 호출 템플릿 check-wait-agg 을 통해 먼저 check-prev 템플릿이 호출되는데, 이것은 진행중인 선행 집계가 있으면 그것의 워크플로우를 강제로 멈추는 역할이다. 이후 wait 템플릿에서 지연 시간을 주는데, 앞서 설명한 것처럼 낭비 집계를 최소화하기 위함이다. 끝으로 agg 템플릿에서 실제 집계 및 결과 업로드가 이루어진다.
다음처럼 ConfigMap 을 만든다.
kubectl create configmap agg-workflow --from-file=agg-workflow.yaml
집계 Sensor 및 테스트
다음과 같은 Sensor 매니페스트를 agg-sensor.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: agg
spec:
template:
# 앞서 만들어둔 Service Account 이용
serviceAccountName: operate-workflow-sa
container:
# 워크플로우 볼륨을 컨테이너에 마운트
volumeMounts:
- name: agg-workflow-vol
mountPath: /workflow
# ConfigMap 에서 워크플로우 볼륨 생성
volumes:
- name: agg-workflow-vol
configMap:
name: agg-workflow
# 의존하는 이벤트
dependencies:
- name: evt-dep
eventSourceName: agg
eventName: put
triggers:
- template:
name: agg-workflow-trigger
k8s:
# 컨테이너에 마운트된 집계 워크플로우 실행 (생성)
operation: create
source:
file:
path: /workflow/agg-workflow.yaml
# 매개변수. MinIO 이벤트 정보 (Notification) 를 읽어 워크플로우의 인자값을 덮어 씀
parameters:
- src:
dependencyName: evt-dep
dataKey: notification.0.s3.bucket.name
dest: spec.arguments.parameters.0.value
- src:
dependencyName: evt-dep
dataKey: notification.0.s3.object.key
dest: spec.arguments.parameters.1.value
앞서 만든 agg EventSource 의 조건에 맞는 MinIO 이벤트가 발생하면, 그 정보 (버킷 이름과 오브젝트 키) 를 인자값으로 하여 쿠버네티스에서 워크플로우 객체를 생성, 실행하게 된다.
다음처럼 Sensor 를 생성한다.
kubectl apply -f agg-sensor.yaml
이제 모든 준비가 끝났다. 아까처럼 MinIO UI 에서 Upload Folder 로 20230414 폴더를 업로드 하면, 각 원본 파일의 ETL 이 수행된 후 집계까지 진행될 것이다.
이 과정에서 집계는 자기 보다 앞서 시작해서 실행중인 집계 워크플로우가 있으면 그것을 취소한다. 따라서 최종적으로 성공하는 집계는 단 하나일 것이다.
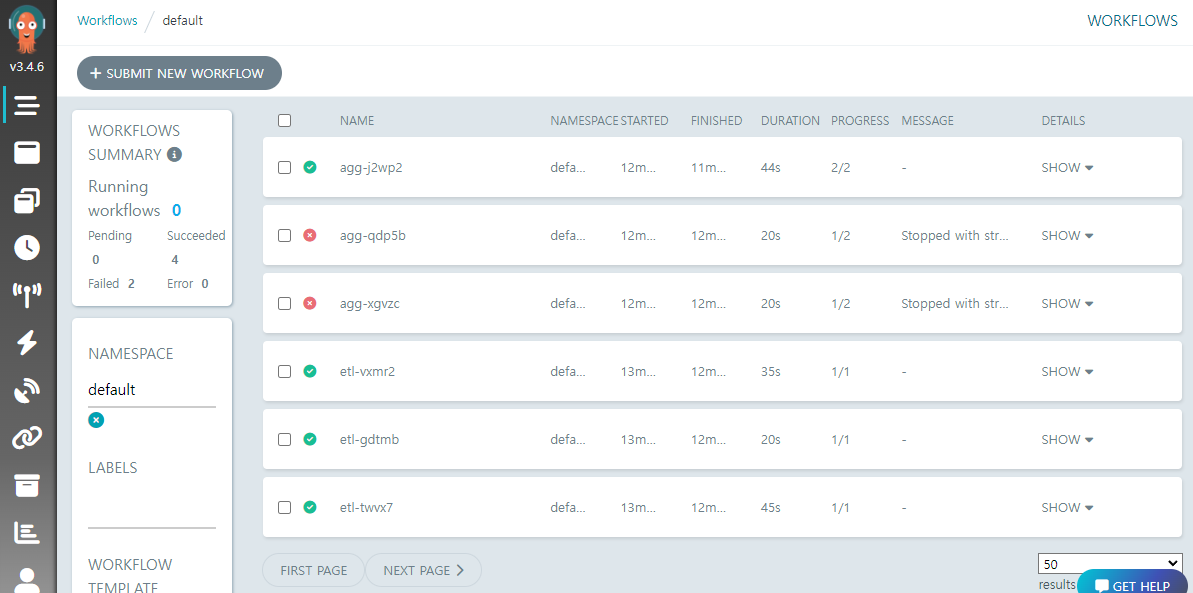
집계 결과는 버킷의 output/agg.txt 에서 확인 가능하며, 내용은 아래와 같을 것이다.
index 2
no 9
name iii
score 100
AWS 환경에서 ETL
이제 로컬 MinIO 가 아닌 AWS 환경에서 S3 를 스토리지로 이용하는 경우를 살펴 보겠다. 원본 파일이 S3 에 올라오면 그 이벤트를 감지하여 ETL 워크플로우를 호출하는 예제이다.
이 예제는 독자가 기본적인 AWS 관련 지식이 있는 것으로 가정한다.
지금까지는 로컬 쿠버네티스 환경에서 실습하였으나, 이 예제에서는 편의상 AWS 상에 EC2 리눅스 인스턴스를 하나 만들어 진행하겠다. S3 이벤트 발생시 Argo Events 는 Webhook 을 통해 SNS 에서 메시지를 받게 되는데, EC2 인스턴스에서 이를 수신하고 워크플로우도 실행하는 용도이다.
만약 자신의 PC 가 외부에서 접근 가능한 환경이라면, 워크플로우 실행은 별도의 EC2 인스턴스 생성없이 지금까지 사용하던 환경에서 진행해도 될 것이다.
예제를 위한 S3 버킷을 하나 생성하고, 대상 버킷의 input/ 폴더 아래에 .csv 파일이 올라오고, output/ 폴더에 ETL 결과물이 저장되는 것으로 가정하겠다.
EC2 인스턴스 생성
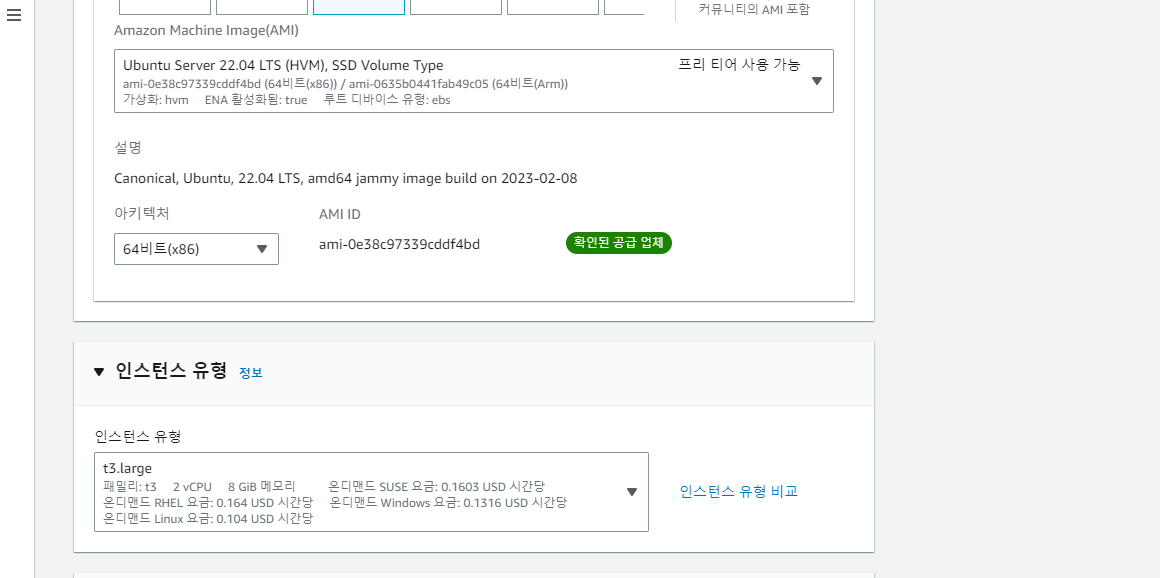
AWS UI (Management Console) 에서 EC2 인스턴스를 만들자. argo-test 라는 이름으로 OS 는 Ubuntu, 유형은 t3.large, 스토리지는 20GB 정도로 하자. 인스턴스가 준비되었으면 다음과 같은 포트들을 보안 그룹에서 오픈한다:
8046- Argo Workflows UI (소스: 내 IP)12000- Argo Events Webhook (소스: Anywhere IPv4)
그 다음 Public IP 를 확보 후 SSH 로 접속하여 Docker 와 minikube, kubectl, Helm 설치를 설치한다.
minikube start 로 클러스터 시작 후, 처음처럼 Argo Events / Workflows 도 설치한다.
앞에서 처럼 외부에서 UI 페이지 접속을 위해서 다음과 같이 한다
# Argo Workflows UI
kubectl port-forward svc/awf-argo-workflows-server --address 0.0.0.0 8046:80
이외에도 워크플로우 용 Service Account 만들기 등 minikube 에서 한 작업을 반복한다.
AWS SNS 주제 및 IAM 사용자 생성
다음으로 AWS SNS 의 주제 (토픽) 을 만들어야 하는데, 이 과정에서 다양한 권한 및 엔드포인트 체크가 이루어 지기에 조심스럽게 진행하도록 하자.
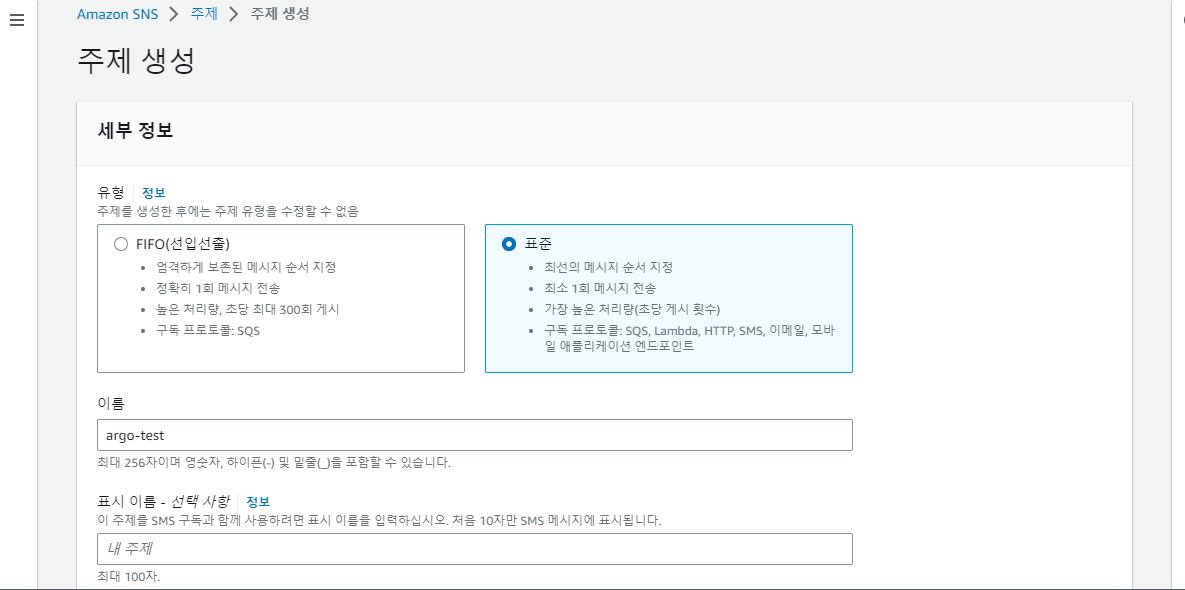
먼저 이벤트를 모니터링할 S3 버킷의 ARN (Amazon Resource Names) 을 복사해두고, 다음으로 AWS UI 의 SNS 페이지로 가서 argo-test 이름으로 표준 유형 주제를 만든다.
이때 S3 버킷이 이 SNS 주제에 발행 (Publish) 할 수 있도록 권한 설정이 필요하다. 액세스 정책 의 고급 JSON 편집기에서 Condition 아래에 다음처럼 ArnLike 필드를 추가하고, 원래있던 SourceOwner 를 SourceAccount 로 변경한다.
"Condition": {
"StringEquals": {
"AWS:SourceAccount": "AWS 사용자 계정 (채워져 있음)"
},
"ArnLike": {
"AWS:SourceArn": "<S3 버킷의 ARN>"
}
}
이제 주제를 생성하고, 주제 ARN 을 확보한다.
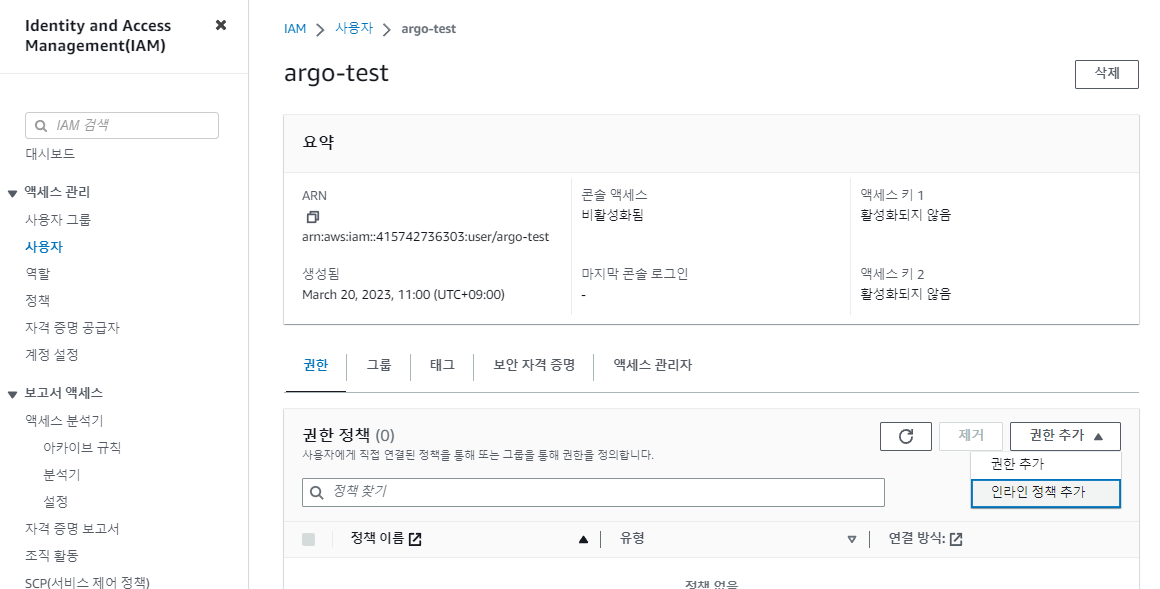
다음은 AWS SNS 메시지를 받기위한 IAM 사용자가 필요하다. 먼저 AWS UI 의 IAM 페이지에서 사용자 argo-test 을 만든다.
주의 :
AWS Management Console 에 대한 사용자 액세스 권한 제공은 선택하지 않도록 하자!
생성 후 해당 사용자 페이지로 이동하고 권한 추가 의 인라인 정책 추가 를 클릭하여 JSON 탭에서 아래와 같은 인라인 정책을 추가하고 argo-test 라고 이름 짓자.
{
"Version": "2008-10-17",
"Id": "$POLICY_ID",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "s3.amazonaws.com"
},
"Action": [
"SNS:Publish"
],
"Resource": "<SNS 토픽 ARN>",
"Condition": {
"ArnLike": {
"AWS:SourceArn": "arn:aws:s3:::<S3 버킷 명>"
}
}
}
]
}
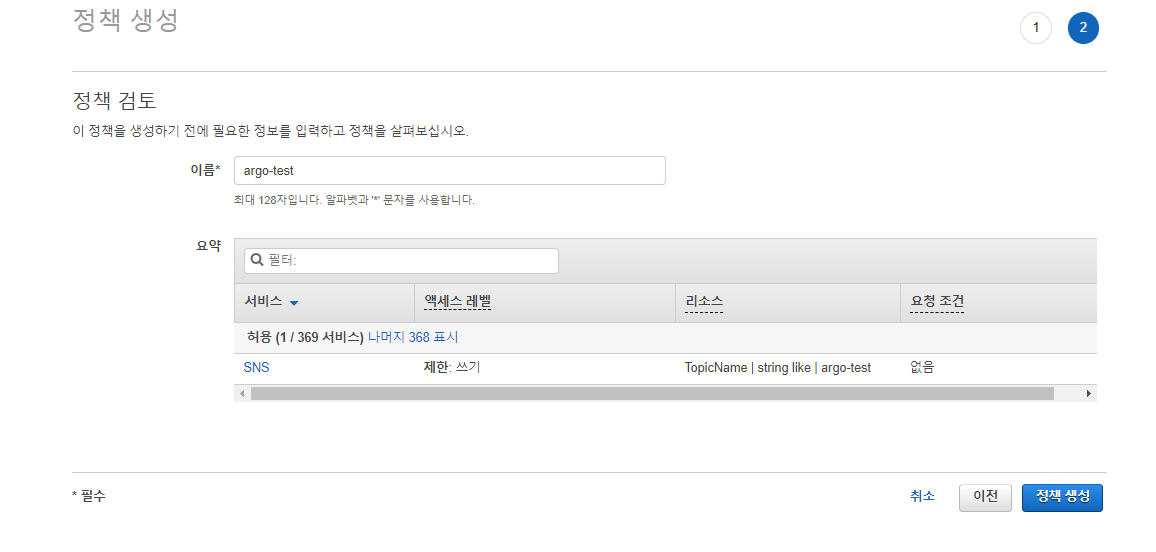
정책 생성 클릭 후 해당 사용자의 보안자격 증명 탭에서 액세스 키 만들기, 로컬 코드 를 선택해 Access Key 와 Secret Key 를 따로 저장해 둔다.
이제 EC2 인스턴스로 돌아가 다음처럼 base64 로 인코딩한 값을 확보하고,
echo -n 'Access Key 값' | base64
echo -n 'Secret Key 값' | base64
다음처럼 sns-credential 이라는 이름의 Secret 리소스 을 만든다.
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: sns-credential
type: Opaque
data:
accessKey: <base64 인코딩한 Access Key>
secretKey: <base64 인코딩한 Secret Key>
EOF
SNS 이벤트 소스 만들기
이제 S3 이벤트를 SNS 를 통해 받기 위해 다음과 같은 내용으로 Argo Events 의 이벤트 소스를 기술하고, etl-evtsrc.yaml 파일에 저장한다.
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: etl
spec:
service:
ports:
- port: 12000
targetPort: 12000
sns:
put:
# SNS 주제의 ARN
topicArn: <생성한 SNS 주제의 ARN>
# 훅은 이벤트 소스에서 실행되는 HTTP 서버 설정을 포함하는데, AWS 는 이곳으로 이벤트를 보낸다.
webhook:
# 접속 정보
endpoint: "/"
port: "12000"
method: POST
# AWS 에 등록할 이벤트 소스 서비스 URL (여기서는 Public IP).
url: http://<인스턴스 URL>
# 생성한 IAM 사용자의 증명 정보
accessKey:
name: sns-credential
key: accessKey
secretKey:
name: sns-credential
key: secretKey
# AWS 리전
region: ap-northeast-2
다음과 같이 적용한다.
kubectl apply -f etl-evtsrc.yaml
문제가 없다면 SNS 주제를 리스닝하는 Webhook 서버가 동작하게 된다. 다음처럼 확인할 수 있다.
$ k get svc | grep eventsource
etl-eventsource-svc ClusterIP 10.97.228.174 <none> 12000/TCP 29s
만약 여기서 확인되지 않는다면 EventBus 를 생성했는지 확인해보자.
다음처럼 포트포워딩도 해준다.
kubectl port-forward svc/etl-eventsource-svc --address 0.0.0.0 12000
SNS 와 S3 연결
AWS UI 의 SNS 페이지로 돌아와 생성한 주제의 구독 생성을 클릭한다.
프로토콜드롭다운에서HTTP를 선택한다.엔드포인트에http://<인스턴스 Public IP>:12000/를 기입한다.구독생성을 누른다.
구독이 제대로 동작하기 위해서는 확인이 필요하다. 왼쪽 패널에서 구독을 눌러 구독 리스트로 가면 좀 전에 생성한 구독이 확인 대기 중 상태인 것을 알 수 있다. 잠시 후 확인이 성공하면 구독에 대한 ID 가 배정된다.
만약 여기에서
알 수 없는 오류에러가 발생하면, 외부에서 Argo EventSource 의 웹훅의 엔드포인트에 접속이 잘 되는지 확인해보자.
이제 모니터링할 S3 버킷에 이벤트 알림을 구성한다.
- AWS UI 의 S3 페이지로 가서 대상 버킷을 선택
속성탭으로 이동 후이벤트 알림을 찾아이벤트 알림 생성을 클릭한다이벤트 이름에argo-test을 입력하고,이벤트 유형의객체 생성란에서전송을 선택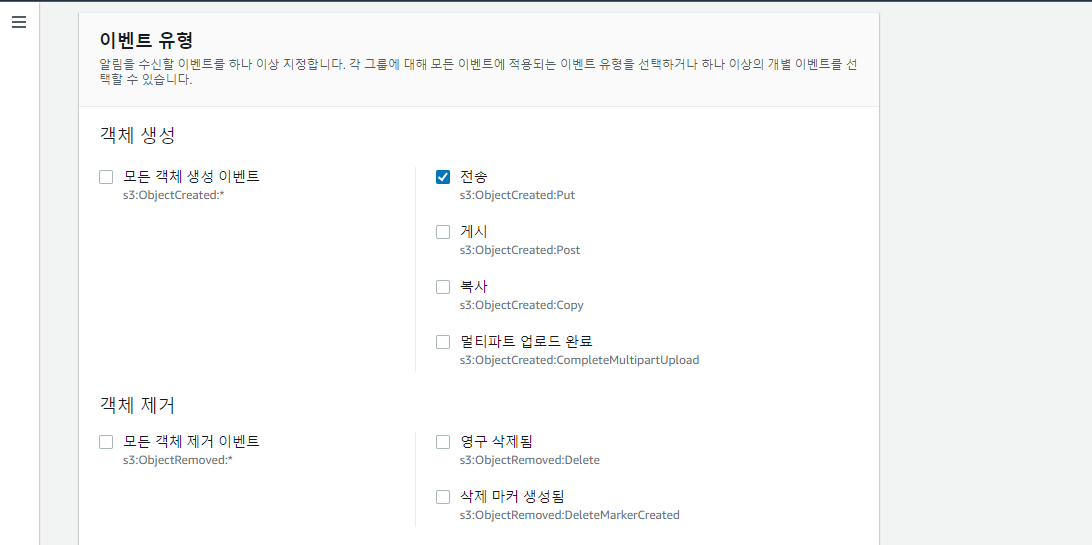
대상에서SNS 주제선택- 나타난
SNS 주제드롭다운에서argo-test선택 변경 사항 저장클릭
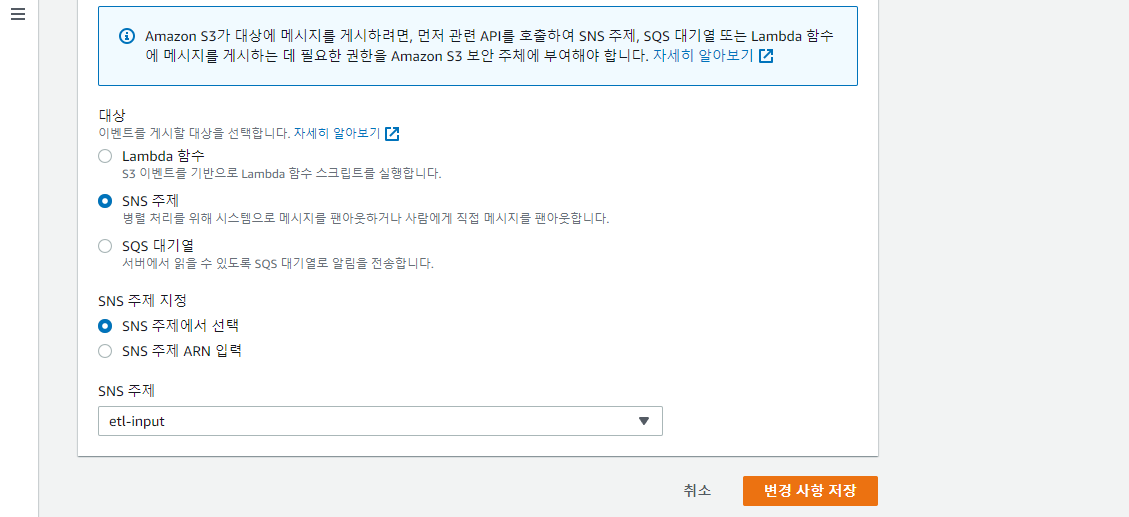
이벤트 소스 파드의 로그를 통해 문제가 없는지 확인하자.
이제 Argo Workflows 관련하여 앞선 예제에서 살펴본 다음과 같은 작업을 EC2 인스턴스에서 반복한다.
etl.py파일과 그로부터 ConfigMap 만들기- 워크플로우 용 Service Account 만들기
- 워크플로우 파일과 그로부터 ConfigMap 만들기
- 센서 만들기
대부분 비슷한 작업으로 차이가 있는 것 위주로 언급하겠다.
ETL 코드 수정
etl.py 는 SNS 메시지에서 버킷과 키 정보를 추출하여 S3 에서 파일을 받도록 변경되었다.
import os
import sys
import csv
import json
import boto3
import pandas as pd
# S3 접속 정보
ACCESS_KEY = os.environ['S3_ACCESS_KEY'].strip()
SECRET_KEY = os.environ['S3_SECRET_KEY'].strip()
# SNS Message 에서 정보 추출
SNSMSG = sys.argv[1]
msg = json.loads(SNSMSG)['Message']
frec = json.loads(msg)['Records'][0]
BUCKET = frec['s3']['bucket']['name']
IN_KEY = frec['s3']['object']['key']
IN_FILE = f'/tmp/{os.path.basename(IN_KEY)}'
OUT_KEY = IN_KEY.replace('input/', 'output/').replace('.csv', '.parquet')
OUT_FILE = '/tmp/output.parquet'
NAMES = ['no', 'name', 'score']
# S3 에서 입력 오브젝트 내려받기
client = boto3.client('s3', aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_KEY)
client.download_file(BUCKET, IN_KEY, IN_FILE)
# Pandas 를 통해 CSV 를 읽고, Parquet 로 저장
df = pd.read_csv(IN_FILE, names=NAMES)
df.to_parquet(OUT_FILE)
# S3 에 결과 업로드
client.upload_file(OUT_FILE, BUCKET, OUT_KEY)
print(f'Processed {len(df)} lines.')
새 내용을 반영하기 위해 기존 ConfigMap 을 삭제 후 다시 생성한다.
kubectl delete configmap etl-code
kubectl create configmap etl-code --from-file=etl.py
대상 S3 버킷 접근 정보
ETL 코드를 위해서는 대상 S3 버킷의 input/ 아래 파일들을 읽고, output/ 아래에 결과 파일을 쓸 수 있어야 한다. AWS UI 에서 아래와 같은 인라인 정책을 가지는 argo-test-s3 라는 이름의 IAM 유저를 앞에서와 같은 식으로 하나 만들자.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<S3 버킷 명>",
"arn:aws:s3:::<S3 버킷 명>/*"
]
}
]
}
앞에서 처럼 AccessKey / SecretKey 도 만들고, 이를 이용해 s3-credential 이라는 이름의 Secret 을 만들자.
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: s3-credential
type: Opaque
data:
accessKey: <base64 인코딩한 Access Key>
secretKey: <base64 인코딩한 Secret Key>
EOF
워크플로우 만들기
etl-workflow.yaml 파일의 경우 코드에 넘겨주는 환경변수가 S3 에 관한 것으로 변경되었다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: etl- # 워크플로우 생성 이름
spec:
# 시작 템플릿
entrypoint: etl
# 인자값. 버킷과 키 (이벤트가 발생될 때 건네진다.)
arguments:
parameters:
- name: snsmsg
# ETL 템플릿을 정의
templates:
- name: etl
inputs:
# 매개변수
parameters:
- name: snsmsg
container:
image: haje01/argo-etl:0.1.5
command: [python]
args: ['/code/etl.py', '{{inputs.parameters.snsmsg}}']
# 대상 S3 버킷에 읽기/쓰기 가ccessKey / SecretKey 를 Secret 에서 환경변수로 전달
env:
- name: S3_ACCESS_KEY
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: s3-credential
key: accessKey
- name: S3_SECRET_KEY
valueFrom: # 환경 변수의 값 소스
secretKeyRef:
name: s3-credential
key: secretKey
# 코드 볼륨을 컨테이너에 마운트
volumeMounts:
- name: etl-vol
mountPath: /code
volumes:
# ConfigMap 에서 코드 볼륨 생성
- name: etl-vol
configMap:
name: etl-code
새 내용을 반영하기 위해 기존 ConfigMap 을 삭제 후 다시 생성한다.
kubectl delete configmap etl-workflow
kubectl create configmap etl-workflow --from-file=etl-workflow.yaml
센서 만들기
etl-sensor.yaml 파일의 경우 매개변수에 SNS 메시지를 받도록 수정되었다.
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: etl
spec:
template:
# 앞서 만들어둔 Service Account 이용
serviceAccountName: operate-workflow-sa
container:
# 워크플로우 볼륨을 컨테이너에 마운트
volumeMounts:
- name: etl-workflow-vol
mountPath: /workflow
# ConfigMap 에서 워크플로우 볼륨 생성
volumes:
- name: etl-workflow-vol
configMap:
name: etl-workflow
# 의존하는 이벤트
dependencies:
- name: evt-dep
eventSourceName: etl
eventName: put
triggers:
- template:
name: etl-workflow-trigger
k8s:
# 컨테이너에 마운트된 ETL 워크플로우 실행 (생성)
operation: create
source:
file:
path: /workflow/etl-workflow.yaml
# 매개변수. S3 이벤트 정보 (Notification) 를 읽어 워크플로우의 인자값을 덮어 씀
parameters:
- src:
dependencyName: evt-dep
dataKey: body
dest: spec.arguments.parameters.0.value
다음처럼 적용하자
kubectl apply -f etl-sensor.yaml
테스트하기
AWS UI 에서 대상 버킷의 input 폴더 아래에 앞에서 만들어둔 test.csv 를 업로드해보면,
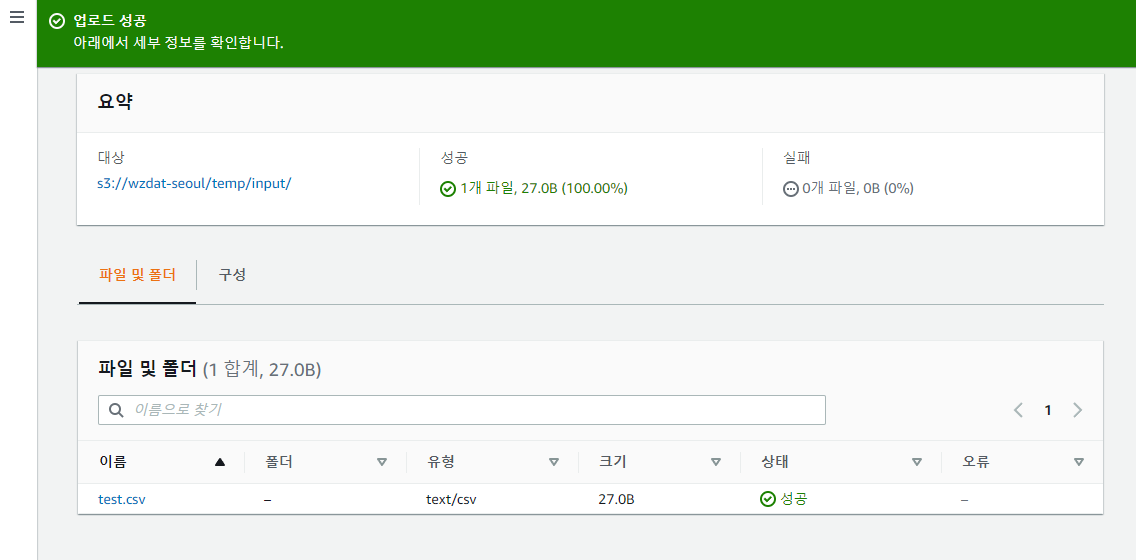
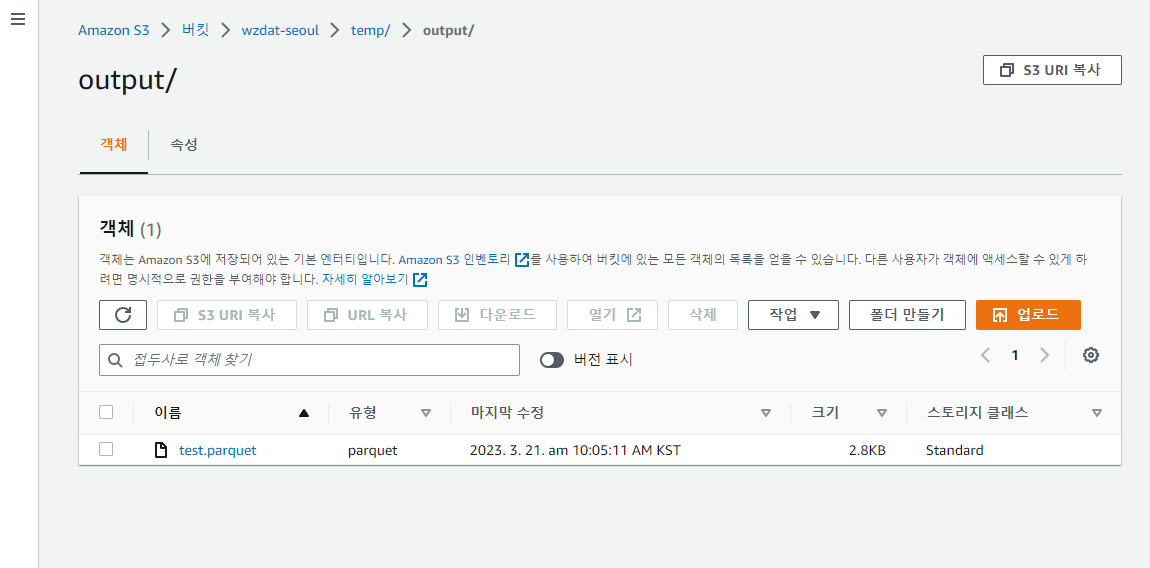
대상 버킷의 output 폴더 아래에 ETL 결과물인 output.parquet 가 생성되는 것을 확인할 수 있다.
AWS 를 사용하는 예제는 여기까지다.
주의 : 실습이 끝났으면 필요없는 AWS 리소스는 제거하여 비용을 절감하도록 하자.
커스텀 (FTP) 이벤트 소스 예제
지금부터는 다시 로컬 minikube 환경에서 진행하는데, 원본 데이터가 FTP 에 올라오는 경우를 가정하여 커스텀 이벤트 소스를 만드는 방법을 알아보겠다.
Argo Events 는 FTP 이벤트 소스를 지원하지 않는다. 그렇지만 앞에서 언급한 제네릭 이벤트 소스 와 커스텀 이벤트 서버를 이용해 FTP 를 위한 이벤트 소스를 구현할 수 있다.
이 예제를 이해하기 위해서는 약간의 gRPC 지식이 필요하다. Introduction 및 Quick Start 정도로 시작해보자.
아래 그림은 이벤트 발생 후 이벤트 소스 서버를 통해 작업이 시작되기까지의 흐름이다.

FTP 서버 설치
먼저 FTP 서버를 하나 띄우겠다. 아래 내용을 vsftpd.yaml 로 저장한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: vsftpd
spec:
selector:
matchLabels:
app.kubernetes.io/name: vsftpd
template:
metadata:
labels:
app.kubernetes.io/name: vsftpd
spec:
containers:
- name: vsftpd
image: fauria/vsftpd
ports:
- containerPort: 21
- containerPort: 20
- containerPort: 30020
- containerPort: 30021
env:
- name: FTP_USER
value: admin
- name: FTP_PASS
value: djemals
- name: PASV_ADDRESS_RESOLVE
value: "YES"
- name: PASV_ADDR_RESOLVE
value: "YES"
- name: PASV_MIN_PORT
value: "30020"
- name: PASV_MAX_PORT
value: "30021"
- name: PASV_ADDRESS_ENABLE
value: "YES"
- name: PASV_ENABLE
value: "YES"
- name: LOG_STDOUT
value: "1"
---
apiVersion: v1
kind: Service
metadata:
name: vsftpd
spec:
selector:
app.kubernetes.io/name: vsftpd
ports:
- name: ftp21
port: 21
targetPort: 21
nodePort: 30025
- name: ftp20
port: 20
targetPort: 20
nodePort: 30026
- name: pasv-min
port: 30020
targetPort: 30020
nodePort: 30020
- name: pasv-max
port: 30021
targetPort: 30021
nodePort: 30021
type: NodePort
FTP 사용자는 admin FTP 사용자 암호는 djemals 이다. 이를 이용해 이후 서버가 FTP 접속을 위해 ftp-secret 이라는 이름의 Secret 을 만든다.
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: ftp-secret
type: Opaque
data:
user: YWRtaW4= # base64 인코딩한 FTP 유저 이름
password: ZGplbWFscw== # base64 인코딩한 FTP 유저 암호
EOF
이제 다음처럼 적용하면
kubectl apply -f vsftpd.yaml
FTP 서버가 동작한다. 접속을 위해서는 포트포워딩이 필요한데, 쿠버네티스 내에 존재하는 FTP 서버는 Passive 모드로 접속해야 하기에 다음처럼 패시브 접속을 위한 포트들도 포워딩 해주어야 한다.
kubectl port-forward svc/vsftpd --address 0.0.0.0 2121:21
kubectl port-forward svc/vsftpd --address 0.0.0.0 30020
kubectl port-forward svc/vsftpd --address 0.0.0.0 30021
FTP 클라이언트를 통해 직접 FTP 서버에 접속하려면 다음처럼 한다.
ftp -p localhost 2121
이벤트 서버와 이벤트 소스 만들기
이제 FTP 이벤트 소스를 위한 서버가 필요한데, 이것을 이벤트 서버 로 부르겠다. 이벤트 서버는 다음과 같은 gRPC 계약 (Contract) 을 충족해야 한다. 이후 작업을 위해 ftp-evtsrv-code/ 디렉토리를 만들고 그쪽으로 이동 후, 아래 내용을 generic.proto 파일로 저장하자.
syntax = "proto3";
package generic;
service Eventing {
rpc StartEventSource(EventSource) returns (stream Event);
}
message EventSource {
// The event source name.
string name = 1;
// The event source configuration value.
bytes config = 2;
}
/**
* Represents an event
*/
message Event {
// The event source name.
string name = 1;
// The event payload.
bytes payload = 2;
}
파이썬으로 gRPC 를 이용하기 위해 로컬 PC 에서 다음과 같이 패키지를 설치한다.
pip install --no-cache-dir grpcio
pip install --no-cache-dir grpcio-tools
프로토콜버퍼 컴파일러를 통해 gRPC 관련 모듈을 생성한다.
python -m grpc_tools.protoc -I=. --python_out=. --pyi_out=. --grpc_python_out=. generic.proto
다음과 같은 파일들이 생성된다.
generic_pb2.py
generic_pb2.pyi
generic_pb2_grpc.py
이벤트 서버 코드는 아래와 같다. ftp-evtsrv.py 로 저장하자.
import os
import sys
import json
import time
import logging
from ftplib import FTP
from concurrent import futures
import yaml
import grpc
import generic_pb2
import generic_pb2_grpc
LOG_FMT = '%(asctime)s %(levelname)s : %(message)s'
DT_FMT = '%Y-%m-%d %H:%M:%S'
# 로그 초기화
logging.basicConfig(format=LOG_FMT, datefmt=DT_FMT)
log = logging.getLogger()
log.setLevel(logging.INFO)
# FTP 접속 정보
FTP_USER = os.getenv('FTP_USER')
assert FTP_USER is not None
FTP_PASSWD = os.getenv('FTP_PASSWD')
assert FTP_PASSWD is not None
def _append_file(files, line, szfield, dtfields):
fields = line.split()
if len(fields) >= 9:
fname = fields[-1]
sz = fields[szfield]
dt = ' '.join([fields[i] for i in dtfields])
dt = f'{fields[-4]} {fields[-3]} {fields[-2]}'
info = dict(sz=sz, dt=dt)
files[fname] = info
def init_ftp(cfg):
"""FTP 연결."""
host = cfg.get('host')
sdir = cfg.get('dir')
pasv = cfg.get('passive')
log.info(f"FTP Connect: {host}")
ftp = FTP(host)
if pasv:
log.info("Use passive mode.")
ftp.set_pasv(True)
ftp.login(user=FTP_USER, passwd=FTP_PASSWD)
ftp.cwd(sdir)
return ftp
class Eventing(generic_pb2_grpc.EventingServicer):
"""
- 처음 StartEventSource 가 불리워질 때 이전 파일 기록 초기화
- 이후로 새로 생성된 파일 정보는 'new' 변경된 파일 정보는 'mod' 로 보냄
- 재시작 등의 이유로 StartEventSource 가 다시 불리워지면 그 사이에 변경은 놓칠 수 있음
"""
def StartEventSource(self, request, context):
# 설정파일 읽기
scfg = request.config.decode('utf8')
log.info(f"StartEventSource: {scfg}")
cfg = yaml.safe_load(scfg)
ftp = init_ftp(cfg)
szfields = cfg.get('szfield')
dtfields = cfg.get('dtfields')
prev_files = {}
# 초기 파일 정보 수집
ftp.retrlines('LIST -R', lambda line: _append_file(prev_files, line, szfields, dtfields))
pcnt = len(prev_files)
if pcnt > 0:
log.warning(f"Ignore {pcnt} previously existing files :")
for fname in prev_files.keys():
log.warning(f" {fname}")
# FTP 파일 변경을 모니터링
while True:
# 10 초에 한 번씩 바뀐 파일 검사
time.sleep(10)
cur_files = {}
try:
# 현재 파일 정보 수집
ftp.retrlines('LIST -R', lambda line: _append_file(cur_files, line, szfields, dtfields))
except Exception as e:
se = str(e)
if 'Timeout' in se:
log.warning("FTP timeout. Reconnect.")
ftp = init_ftp(cfg)
continue
else:
log.error(se)
raise e
# 새로운 또는 갱신된 파일 정보 전송
for fname, info in cur_files.items():
event = None
if fname not in prev_files:
event = 'new'
log.info(f"New file: {fname}, Info: {info}")
info = dict(name=fname, sz=info['sz'], dt=info['dt'])
else:
pinfo = prev_files[fname]
if info['sz'] != pinfo['sz'] or info['dt'] != pinfo['dt']:
event = 'mod'
info = dict(name=fname, sz=info['sz'], dt=info['dt'])
log.info(f"Modified file: {fname}, Info: {info}")
payload = json.dumps(info).encode()
# 생성 / 변경된 파일이 있으면 알림
if event is not None:
payload = json.dumps(info).encode()
yield generic_pb2.Event(name=event, payload=payload)
prev_files[fname] = info
def serve():
port = '50051'
server = grpc.server(futures.ThreadPoolExecutor(max_workers=1))
generic_pb2_grpc.add_EventingServicer_to_server(Eventing(), server)
server.add_insecure_port('[::]:' + port)
server.start()
log.info("Server started, listening on " + port)
server.wait_for_termination()
if __name__ == '__main__':
serve()
이제 ftp-evtsrv-code/ 폴더내 파일은 아래와 같을 것이다.
ftp-evtsrv-code/
ftp-evtsrv.py
generic.proto
generic_pb2.py
generic_pb2.pyi
generic_pb2_grpc.py
이제 상위 폴더로 이동 후, 다음처럼 ftp-evtsrv-code/ 폴더에서 ftp-evtsrv-code ConfigMap 을 생성한다.
kubectl create configmap ftp-evtsrv-code --from-file=ftp-evtsrv-code/
이렇게 하면 해당 폴더의 모든 파일이 ConfigMap 리소스에 들어간다.
FTP 서버 배포를 위해 다음과 같은 내용을 ftp-evtsrv.yaml 로 저장한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: ftp-evtsrv
labels:
app.kubernetes.io/name: ftp-evtsrv
spec:
selector:
matchLabels:
app.kubernetes.io/name: ftp-evtsrv
template:
metadata:
labels:
app.kubernetes.io/name: ftp-evtsrv
spec:
containers:
- name: ftp-evtsrv
image: haje01/argo-etl:0.1.5
command: ['python']
args: ['/code/ftp-evtsrv.py']
ports:
- containerPort: 50051
# FTP 로그인 정보
env:
- name: FTP_USER
valueFrom:
secretKeyRef:
name: ftp-secret
key: user
- name: FTP_PASSWD
valueFrom:
secretKeyRef:
name: ftp-secret
key: password
# 코드 볼륨을 컨테이너에 마운트
volumeMounts:
- name: ftp-evtsrv-code-vol
mountPath: /code
volumes:
# ConfigMap 에서 코드 볼륨 생성
- name: ftp-evtsrv-code-vol
configMap:
name: ftp-evtsrv-code
---
apiVersion: v1
kind: Service
metadata:
name: ftp-evtsrv-svc
spec:
selector:
app.kubernetes.io/name: ftp-evtsrv
ports:
- protocol: TCP
port: 5051
targetPort: 50051
다음처럼 적용한다.
kubectl apply -f ftp-evtsrv.yaml
다음은 이 이벤트 서버로 접속하도록 다음과 같은 Argo Events 의 이벤트 소스를 ftp-evtsrc.yaml 로 저장하고 적용한다.
apiVersion: argoproj.io/v1alpha1
kind: EventSource
metadata:
name: ftp
spec:
generic:
ftp:
insecure: true
url: "ftp-evtsrv-svc:5051"
config: |-
# FTP 호스트 주소
host: vsftpd
# FTP 시작 디렉토리
dir: /
# FTP Passive 모드 여부
passive: true
# 크기 정보 필드
szfield: 4
# 갱신 일시 정보 필드
dtfields: [-4, -3, -2]
다음처럼 적용한다.
kubectl apply -f ftp-evtsrc.yaml
ftp 아래 config 필드에 기술하는 설정값 중 passive 는 FTP 의 Passive 모드 옵션이다. szfield 는 FTP 에서 파일을 LIST 하였을 때, 화이트스페이스 기준으로 몇 번째 필드가 파일의 크기를 나타내는지에 관한 정보이다. 비슷하게 dtfields 는 몇 번째 필드들이 파일의 갱신일시를 구성하는 것인지에 대한 정보이다.
예를 들어 현재 사용하는 vsftp 의 경우 LIST 의 결과가 아래와 같기에,
-rw-r--r-- 1 ftp ftp 123 Mar 23 00:41 test.csv
앞에서부터 5 번째 (0 베이스 인덱스는 4) 필드가 크기 123 을 나타내고, 뒤에서부터 4, 3, 2 번째 필드를 결합하면 Mar 23 00:41 이 되어 일시를 나타내는 것을 알 수 있다.
FTP 서버의 종류에 따라 파일의 갱신 일시는 다양한 형식으로 나올 수 있다. vfsftp 의 경우 분 단위 정밀도만 지원하기에, 더 높은 정밀도가 필요한 경우 FTP 서버의 설정이나 교체를 검토해보자.
ETL 코드, 워크플로우 그리고 센서
아래는 FTP 에서 파일을 내려 받아 ETL 하는 코드이다. ftp-etl.py 로 저장하자.
import os
import sys
import base64
import tempfile
import json
from ftplib import FTP
import pandas as pd
# FTP 접속 정보
FTP_HOST = os.getenv('FTP_HOST')
assert FTP_HOST is not None
FTP_USER = os.getenv('FTP_USER')
assert FTP_USER is not None
FTP_PASSWD = os.getenv('FTP_PASSWD')
assert FTP_PASSWD is not None
payload = base64.b64decode(sys.argv[1]).decode()
info = json.loads(payload)
print(f"FTP Notification: {info}")
# FTP 파일 정보
path = info.get('name')
sz = info.get('sz')
dt = info.get('dt')
in_file = tempfile.mkstemp()[1]
out_file = '/tmp/output.parquet'
cols = ['no', 'name', 'score']
# FTP 에서 소스 파일 내려받기
ftp = FTP(FTP_HOST)
ftp.set_pasv(True) # 필요에 따라 설정
ftp.login(user=FTP_USER, passwd=FTP_PASSWD)
print(f"Download file '{path}'")
with open(in_file, 'wb') as fp:
ftp.retrbinary(f'RETR {path}', fp.write)
# Pandas 를 통해 CSV 를 읽고, Parquet 로 저장
df = pd.read_csv(in_file, names=cols)
df.to_parquet(out_file)
print(f'Processed {len(df)} lines.')
다음처럼 ConfigMap 을 만든다.
kubectl create configmap ftp-etl-code --from-file=ftp-etl.py
이벤트 발생시 위 코드를 실행할 워크플로우도 필요하다. 아래 내용을 ftp-workflow.yaml 로 저장한다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: ftp- # 워크플로우 생성 이름
spec:
# 시작 템플릿 지정
entrypoint: etl
# 인자값. 설정 (이벤트가 발생될 때 건네진다.)
arguments:
parameters:
- name: config
# FTP ETL 템플릿을 정의
templates:
- name: etl
inputs:
# 매개변수
parameters:
- name: config
container:
image: haje01/argo-etl:0.1.5
command: [python]
args: ['/code/ftp-etl.py', '{{inputs.parameters.config}}']
# FTP 사용자 및 암호를 Secret 에서 환경변수로 전달
env:
- name: FTP_HOST
value: vsftpd
- name: FTP_USER
valueFrom:
secretKeyRef:
name: ftp-secret
key: user
- name: FTP_PASSWD
valueFrom:
secretKeyRef:
name: ftp-secret
key: password
# 코드 볼륨을 컨테이너에 마운트
volumeMounts:
- name: etl-vol
mountPath: /code
volumes:
# ConfigMap 에서 코드 볼륨 생성
- name: etl-vol
configMap:
name: ftp-etl-code
outputs:
# 결과 파일에서 출력 아티팩트 생성
artifacts:
- name: output-art # 출력 아티팩트 이름
path: /tmp/output.parquet # 출력 아티팩트 소스 파일
archive: {} # 파케이 파일의 경우 별도 압축하지 않음
아까처럼 ConfigMap 을 만든다.
kubectl create configmap ftp-workflow --from-file=ftp-workflow.yaml
센서는 앞서 만든 FTP 이벤트 소스와 워크플로우를 위해 다음과 같은 내용을 ftp-sensor.yaml 로 저장한다.
apiVersion: argoproj.io/v1alpha1
kind: Sensor
metadata:
name: ftp
spec:
template:
# 앞서 만들어둔 Service Account 이용
serviceAccountName: operate-workflow-sa
container:
# 워크플로우 볼륨을 컨테이너에 마운트
volumeMounts:
- name: ftp-workflow-vol
mountPath: /workflow
# ConfigMap 에서 워크플로우 볼륨 생성
volumes:
- name: ftp-workflow-vol
configMap:
name: ftp-workflow
# 의존하는 이벤트
dependencies:
- name: ftp-dep
eventSourceName: ftp
eventName: ftp
triggers:
- template:
name: ftp-workflow-trigger
k8s:
# 컨테이너에 마운트된 ETL 워크플로우 실행 (생성)
operation: create
source:
file:
path: /workflow/ftp-workflow.yaml
# 매개 변수. ftp 이벤트 정보 (Notification) 를 읽어 워크플로우의 인자값을 덮어 씀
parameters:
- src:
dependencyName: ftp-dep
dataKey: body
dest: spec.arguments.parameters.0.value
다음처럼 적용하자
kubectl apply -f ftp-sensor.yaml
테스트하기
앞서 만들어 두었던 test.csv 파일을 다음처럼 FTP 서버에 접속해 올리면,
$ ftp -p localhost 2121
Connected to localhost.
220 (vsFTPd 3.0.2)
Name (localhost:haje01): admin
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> put test.csv
문제가 없다면 잠시 후 다음처럼 결과 Parquet 파일을 확인할 수 있다.
앞서 만든 FTP 이벤트 서버 -> 이벤트 소스 -> 센서 -> 워크플로우 순으로 진행되어 결과물이 나온 것이다.
기타
여기서는 지금까지 다루지 않았던 것들 중 유용할 수도 있는 기능들을 소개하겠다.
재시도 설정
템플릿 호출이 실패하였을 때 재시도를 할 수 있다. 다양한 방식의 전략을 지원하는데, 주로 사용하는 것은 아래와 같다 (자세한 것은 문서를 참고하자).
limit: 지정한 횟수까지 재시도backoff: 재시도 주기와 지연 시간 등 지정
다음 내용을 retry-script.yaml 로 저장하자.
metadata:
generateName: retry-script-
spec:
# 시작 템플릿
entrypoint: retry-script
templates:
- name: retry-script
retryStrategy:
# 10번까지 재시도
limit: "10"
script:
image: python:alpine3.6
command: ["python"]
# 66% 확률로 실패하게
source: |
import random;
import sys;
exit_code = random.choice([0, 1, 1]);
sys.exit(exit_code)
다음처럼 적용하면,
argo submit --watch hello-world.yaml
결과 코드가 0 이 나올때까지 재시도를 하는데, 다음은 3번의 시도 끝에 성공한 예이다.
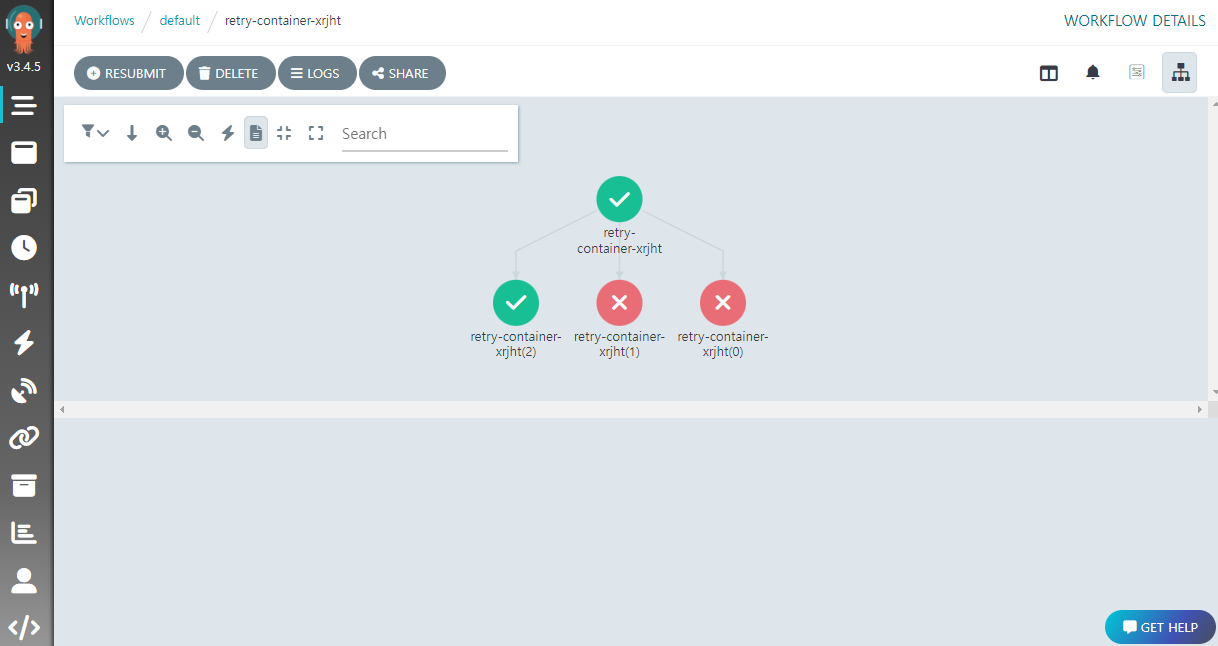
뮤텍스
뮤텍스는 상호 배제 (Mutual Exclusion) 의 약자로, 주로 컴퓨터에서 특정 리소스에 대한 다중 접근을 방지하는데 사용된다. 예를 들어 하나의 파일에 두 개의 프로그램이 동시에 쓰기를 시도하면 잘못된 파일이 생성될 수 있는데, 뮤텍스를 이용해 이런 문제를 방지한다.
템플릿이나 워크플로우도 리소스를 독점적으로 사용할 필요가 있는 경우 뮤텍스를 이용할 수 있다. Argo Workflows 에는 워크플로우 뮤텍스 와, 템플릿 뮤텍스 가 존재한다.
다음은 워크플로우 뮤텍스의 예로 synchronization.mutex 필드 아래에 뮤텍스 이름을 지정하고 있다. 이렇게 하면 특정 네임스페이스 안에서 같은 이름의 뮤텍스를 가진 워크플로우는 동시에 하나만 실행될 수 있다.
synchronization-mutex-wf-level.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: synchronization-wf-level-
spec:
# 시작 템플릿
entrypoint: whalesay
# 워크플로우 레벨의 뮤텍스 지정
synchronization:
mutex:
name: test
templates:
- name: whalesay
container:
image: docker/whalesay:latest
command: [cowsay]
args: ["hello world"]
다음처럼 두 번 연속으로 적용하면,
argo submit synchronization-mutex-wf-level.yaml
argo submit synchronization-mutex-wf-level.yaml
먼저 실행된 워크플로우가 완료될 때까지 다음 워크플로우는 대기하는 것을 확인할 수 있다.
동적인 파드 스펙 지정
때로는 ETL 대상 원본 파일의 크기가 일정하지 않고 다양한 경우가 있다. 이런 경우 파일 크기에 맞추어 ETL 파드의 스펙을 지정할 수 있다면 도움이 될 것이다. 예를 들어 아래와 같은 과정이 될 수 있겠다.
- 선행 단계에서 원본 데이터 크기를 후, 적절한 파드 스펙을 출력
podSpecPatch로 ETL 파드의 스펙을 지정하여 ETL 수행
다음은 이런 동적 파드 스펙을 위한 예제이다. pod-spec-from-previous-step.yaml 로 저장하자.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: pod-spec-from-previous-step-
spec:
# 시작 템플릿
entrypoint: workflow
templates:
# 파일 크기 파악 후 적절한 파드 스펙을 출력하는 템플릿
- name: parse-resources-tmpl
outputs:
parameters:
- name: resources
valueFrom:
path: /tmp/resources.json
script:
image: alpine:latest
command: [sh]
source: |
echo '{"memory": "10Gi", "cpu": "2000m"}' > /tmp/resources.json && cat /tmp/resources.json
# 앞 단계에서 주어진 파드 스펙을 이용하여 작업 파드를 띄우는 템플릿
- name: setup-resources-tmpl
inputs:
parameters:
- name: resources
podSpecPatch: '{"containers":[{"name":"main", "resources":{"limits": {{inputs.parameters.resources}}, "requests": {{inputs.parameters.resources}} }}]}'
script:
image: alpine:latest
command: [sh]
source: |
echo {{inputs.parameters.resources}}
# 멀티 스텝으로 호출
- name: workflow
dag:
tasks:
- name: parse-resources
template: parse-resources-tmpl
- name: setup-resources
depends: "parse-resources"
template: setup-resources-tmpl
arguments:
parameters:
- name: resources
value: "{{tasks.parse-resources.outputs.parameters.resources}}"
setup-resources 에서 가상으로 필요 사양을 생성하고, 그것에 맞게 setup-resources 파드가 실행된다. 해당 파드를 kubectl describe 해보면 다음과 같은 내용을 확인할 수 있다.
Limits:
cpu: 2
memory: 10Gi
Requests:
cpu: 2
memory: 10Gi
워크플로우 템플릿
워크플로우 템플릿 (Workflow Template) 은 공용 워크플로우를 라이브러리처럼 정의해두고, 필요한 곳에서 쉽게 불러서 쓸 수 있게 해준다.
예를 들어 다음처럼 templates.yaml 파일안에 다양한 공용 워크플로우 템플릿으로 정의해 두고 이용할 수 있다.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: workflow-say-tmpl
spec:
entrypoint: say
templates:
- name: say
inputs:
parameters:
- name: message
container:
image: docker/whalesay
command: [cowsay]
args: ["{{inputs.parameters.message}}"]
---
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: workflow-think-tmpl
spec:
entrypoint: think
templates:
- name: think
inputs:
parameters:
- name: message
container:
image: docker/whalesay
command: [cowthink]
args: ["{{inputs.parameters.message}}"]
다음처럼 개별 워크플로우에서 workflowTemplateRef 를 통해 워크플로우 템플릿 전체를 사용하거나,
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: workflow-say-
spec:
entrypoint: say
arguments:
parameters:
- name: message
value: "hello world"
workflowTemplateRef:
name: workflow-say-tmpl
다음처럼 templateRef 를 통해 워크플로우 템플릿내 특정 템플릿을 지정해 이용할 수도 있다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: workflow-think-
spec:
entrypoint: mythink
templates:
- name: mythink
steps:
- - name: call-think-tmpl
templateRef:
name: workflow-think-tmpl
template: think
arguments:
parameters:
- name: message
value: "hello world"
특정 기간에 대한 재작업
여기서는 다음과 같은 상황을 가정한 예제를 소개한다.
- 일별 ETL 워크플로우 템플릿을 작성
- 평소에는 Cron 워크플로우로 기동하다
- 기간 재작업이 필요한 경우 Backfill 수행
다음처럼 ETL 용 워크플로우 템플릿 파일 etl-template.yaml 을 만든다.
# 공용 워크플로우 정의
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: workflow-etl-tmpl
spec:
entrypoint: main
arguments:
parameters:
- name: date
# yesterday 는 매직 밸류
value: yesterday
templates:
- name: main
inputs:
parameters:
- name: date
script:
image: haje01/argo-etl:0.1.5
command:
- sh
source: |
date="{{inputs.parameters.date}}"
# 대상일이 yesterday 인 경우 어제 날짜 구함
if [ $date = yesterday ]; then
date=$(date -d yesterday +%Y-%m-%d)
fi
echo "run ETL for $date"
위 워크플로우 템플릿은 입력 매개변수 date 를 받는데, yesterday 라는 값이 오면 어제 날짜를 직접 구해 사용하고, 그것이 아니면 건네진 날짜를 그대로 이용한다.
다음은 크론 워크플로우 (Cron Workflow) 로 특정 스케쥴 기반으로 실행되는 워크플로우이다.
apiVersion: argoproj.io/v1alpha1
kind: CronWorkflow
metadata:
name: daily-job
spec:
# 매일 새벽 2시에 실행
schedule: "0 2 * * *"
workflowSpec:
workflowTemplateRef:
name: workflow-etl-tmpl
매일 오전 2시에 앞에서 작성한 워크플로우 템플릿을 workflowTemplateRef 으로 참조하여 수행한다.
다음은 빽필 (Backfill) 을 위한 워크플로우로, 지정한 조건으로 워크플로우를 재작업하는 용도이다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
name: backfill
spec:
entrypoint: main
# 동시 실행 가능 한 최대 작업 수
parallelism: 2
templates:
- name: main
steps:
- - name: run-etl
templateRef:
name: workflow-etl-tmpl
template: main
arguments:
parameters:
- name: date
value: "{{item}}"
withSequence:
# 2023 년 4월 7 일부터 11 일까지 ETL 진행
start: "7"
end: "11"
format: "2023-04-%02d"
다음처럼 4월 7일 부터 11 일까지 최대 2 개 ETL 작업이 동시에 실행된다.
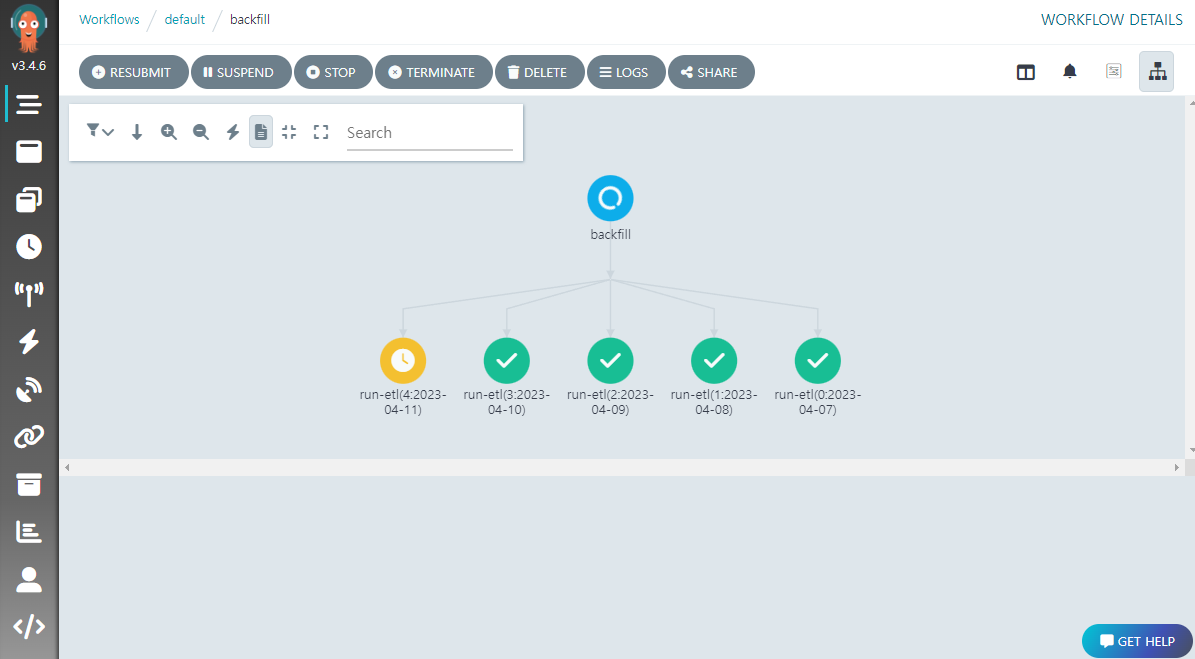
예제의 경우는 날짜를 숫자로 다루고 있어 다른 달로 넘어가는 처리는 되지 않는다. 임의 기간에 대해 제대로 빽필을 구현하는 것은 과제로 남기겠다. 매개 변수로 시작일과 종료일을 받고,
run-etl전단계에서 날짜 리스트를 생성하여 전달하는 식이면 될 것이다.argo submit -p를 이용해 임의의 시간에 대해 재작업도 가능하겠다.
정리
지금까지 Argo Events 및 Workflows 의 사용법을 예제 중심으로 실펴보았다. 공식 문서와 예제에는 더 다양한 내용이 소개되고 있으니, 꼭 방문하여 깊이 있는 활용을 하기 바란다.
참고 링크
https://argoproj.github.io/argo-events https://github.com/argoproj/argo-events https://argoproj.github.io/argo-workflows https://github.com/argoproj/argo-workflows https://coffeewhale.com/kubernetes/workflow/argo/2020/02/14/argo-wf